Watch the video
Quick version? Watch the video. For full context, read the article.
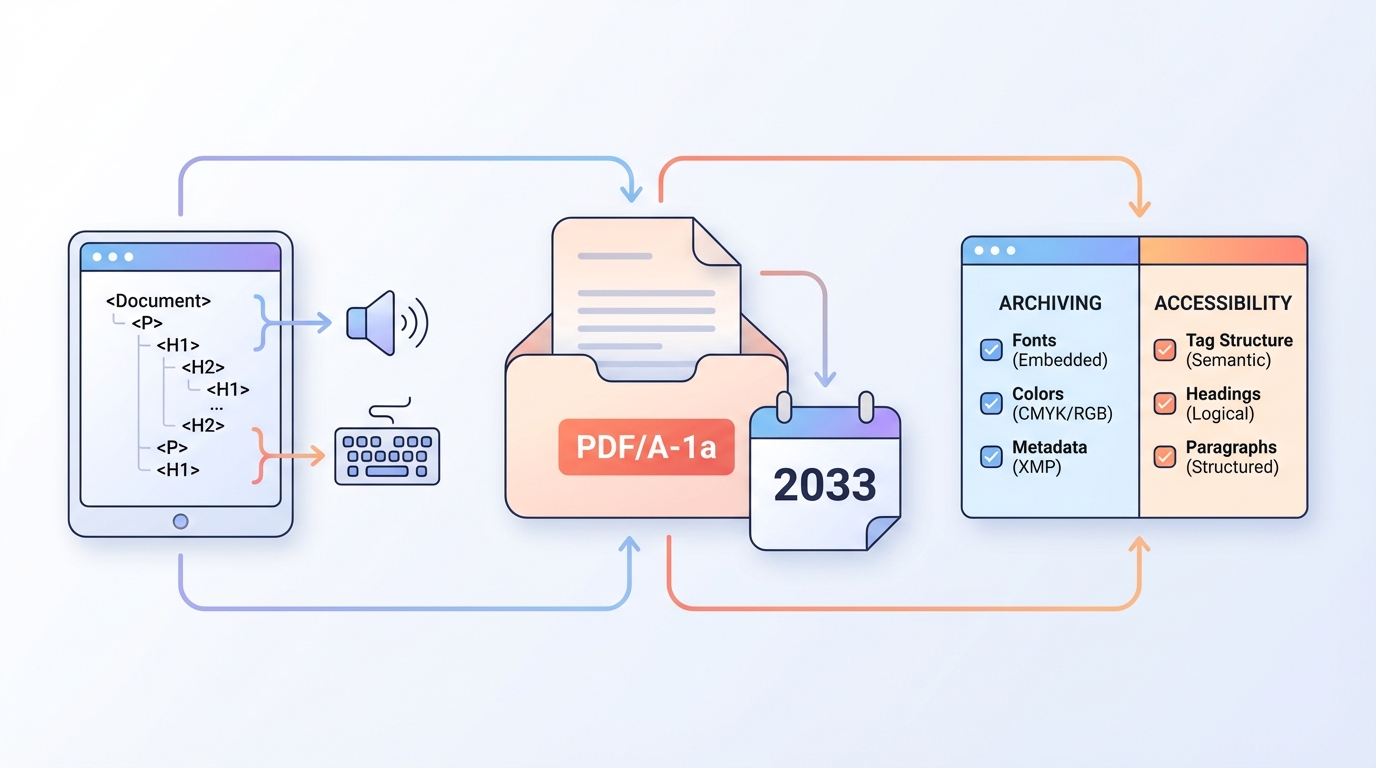
PDF is often the last mile of a pipeline: what you publish must be archivable (long-term preservation) and accessible (usable by everyone).
That’s exactly where things break: PDF/A-1a and PDF/UA look like checkboxes, but in practice they’re a set of concrete requirements that can destabilize your pipeline.
This article explains where teams get stuck — and how to design this as a controlled process instead of “one more export”.
Why this fails so often
Many teams treat PDF as an end-of-project deliverable. They export from Word/HTML or generate via a library. It works… until the output must comply with:
- PDF/A-1a (archival quality, reproducible over time)
- PDF/UA (accessibility: tags, structure, alt text, reading order)
- and sometimes additional portal/industry/government constraints Then the surprises start:
- “veraPDF suddenly fails after a tiny change.”
- “The PDF looks fine visually, but screen readers struggle.”
- “Metadata is off, fonts aren’t embedded, tags are incomplete.”

PDF/A-1a vs PDF/UA in plain English
PDF/A-1a (archiving)
Goal: the document should open and render reliably years from now, independent of external dependencies.
Typical pain points:
- fonts must be fully embedded
- color management/profiles must be correct
- metadata (XMP) must be consistent
- no hidden dependencies (external resources)
PDF/UA (accessibility)
Goal: a PDF with a semantic structure that assistive technologies can understand.
Typical requirements:
- correct tag structure (headings, paragraphs, lists)
- correct reading order
- alt text for images
- tables must be real tables (TH/TD, scope/headers)
- document language and title set correctly
In practice: PDF/A is “the PDF as an archive object”, PDF/UA is “the PDF as a structured document”.
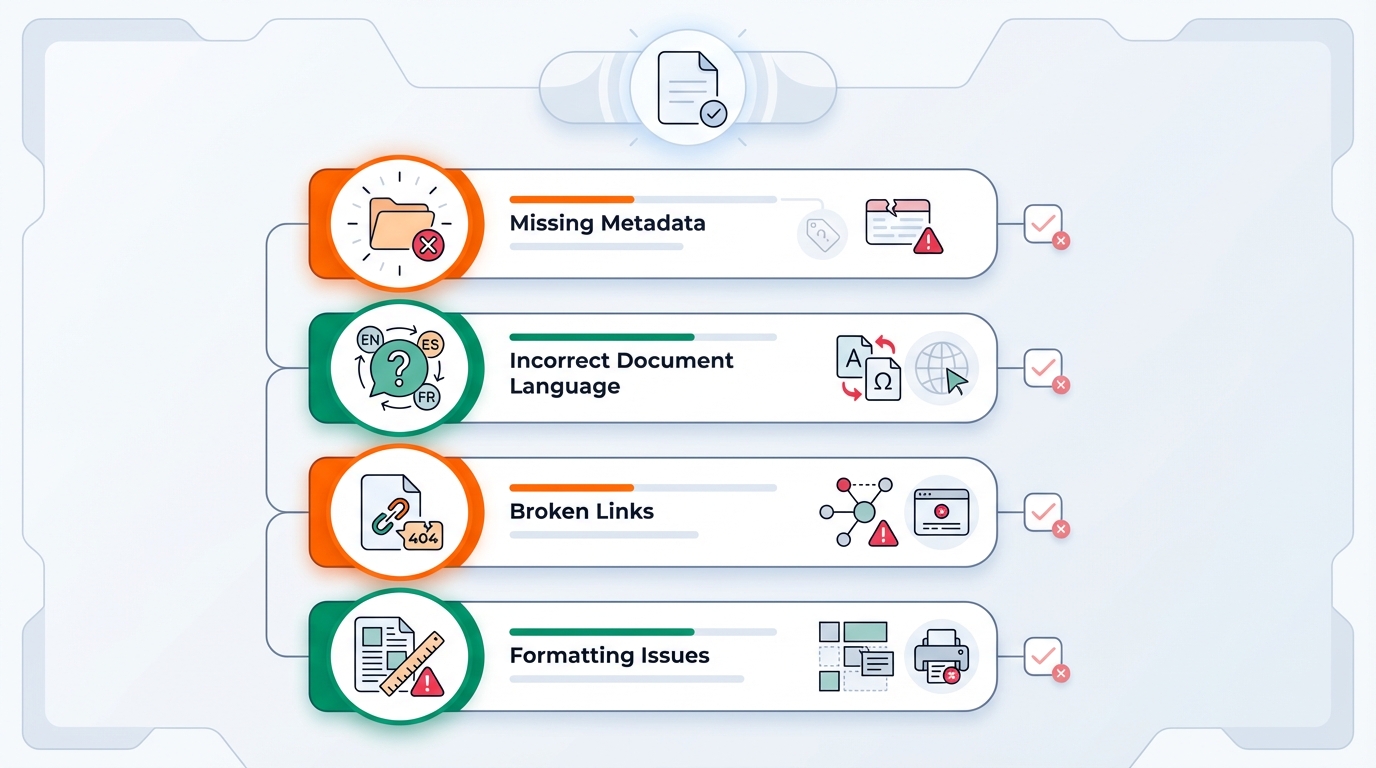
Where it breaks most often (top 10)
- XMP metadata: missing or inconsistent title/author/producer
- Document language missing or wrong
- Title not set (or not configured to display)
- Fonts not fully embedded
- Images missing alt text, or decorative images not marked as artifacts
- Heading levels skip steps (H1 → H3)
- Reading order looks fine visually but is wrong logically
- Tables: missing proper headers / wrong scope
- Links without meaningful link text (“click here”)
- Generator/export produces “almost tags”, but not compliant tags
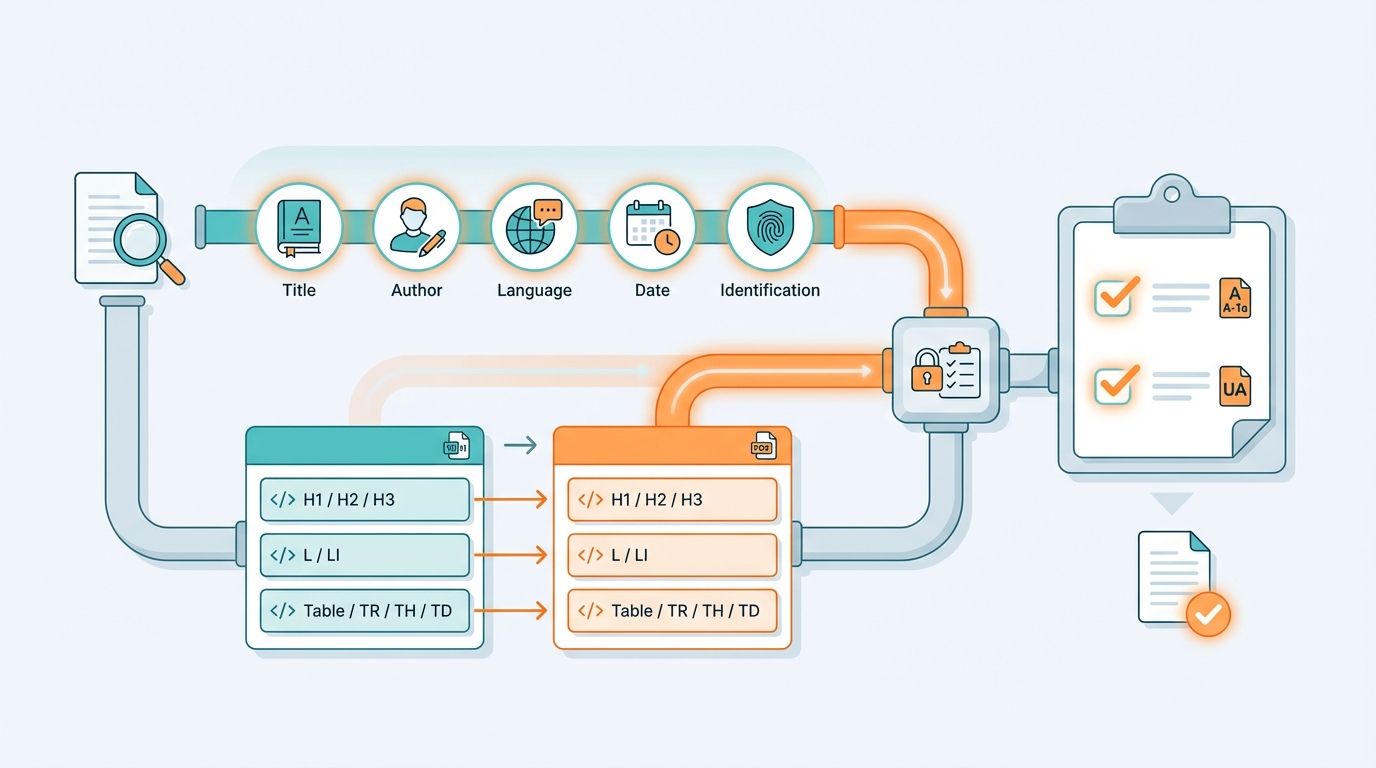
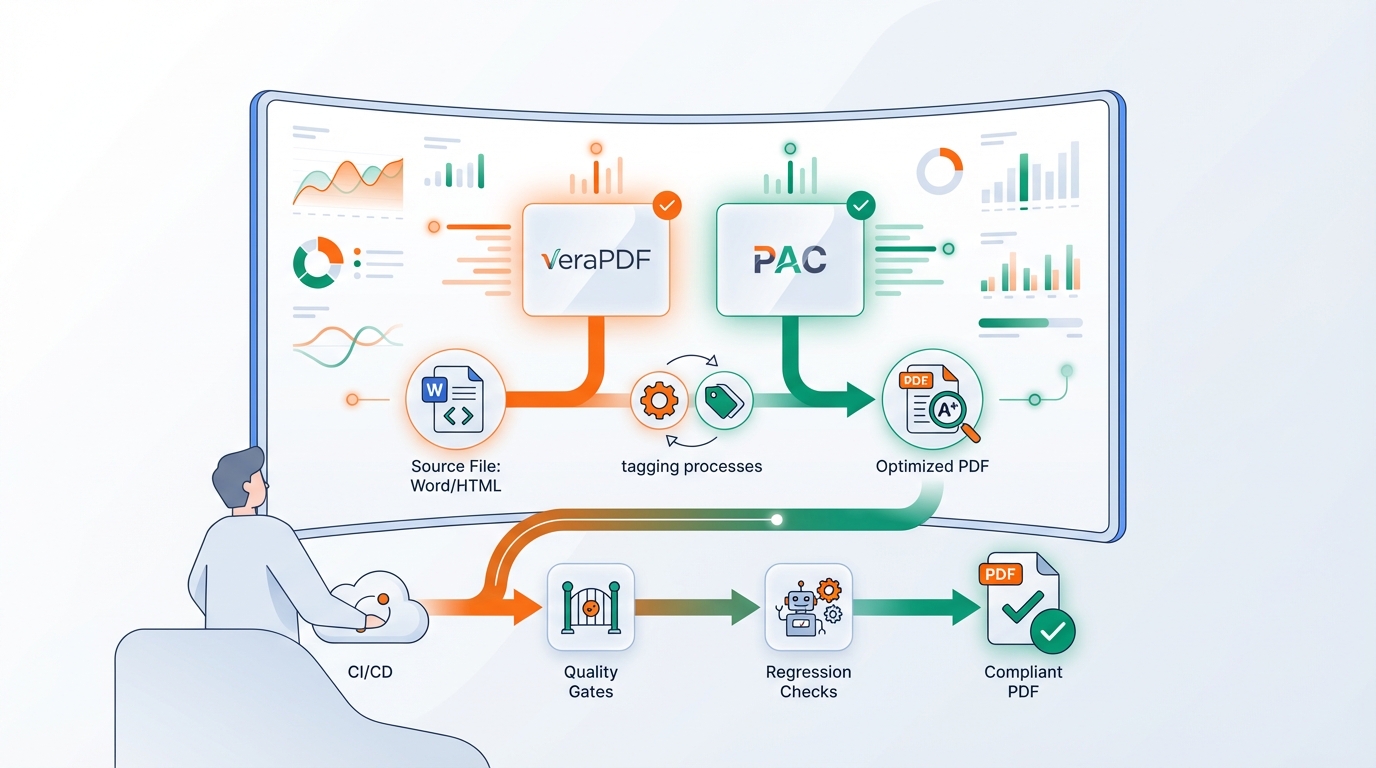
The fix: treat it as a controlled pipeline
The key is to stop treating PDF/A-1a and PDF/UA as “export” and instead implement them as quality gates in your delivery chain.
1) One source of truth for metadata
Decide where title, author, language, date, identifiers come from.
Make it mandatory — like schema validation on XML.
2) Tagging isn’t a side effect
If you generate from Word/HTML, define explicit mapping rules:
- heading styles → H1/H2/H3
- lists → L/LI
- tables → Table/TR/TH/TD
- images → Figure + alt text, or Artifact
3) Quality gates before publishing
Use validators as gates, not as post-mortems:
- veraPDF for PDF/A (and some PDF/UA checks)
- a PDF/UA checker (e.g., PAC) for accessibility
- add your own checks (missing alt text, language, title, etc.)
4) Make failures reproducible
When a PDF fails, you want:
- the exact validator output stored
- the source input + version stored
- a clear diff of what changed (generator, stylesheets, templates)
That’s how you avoid “mystery regressions”.
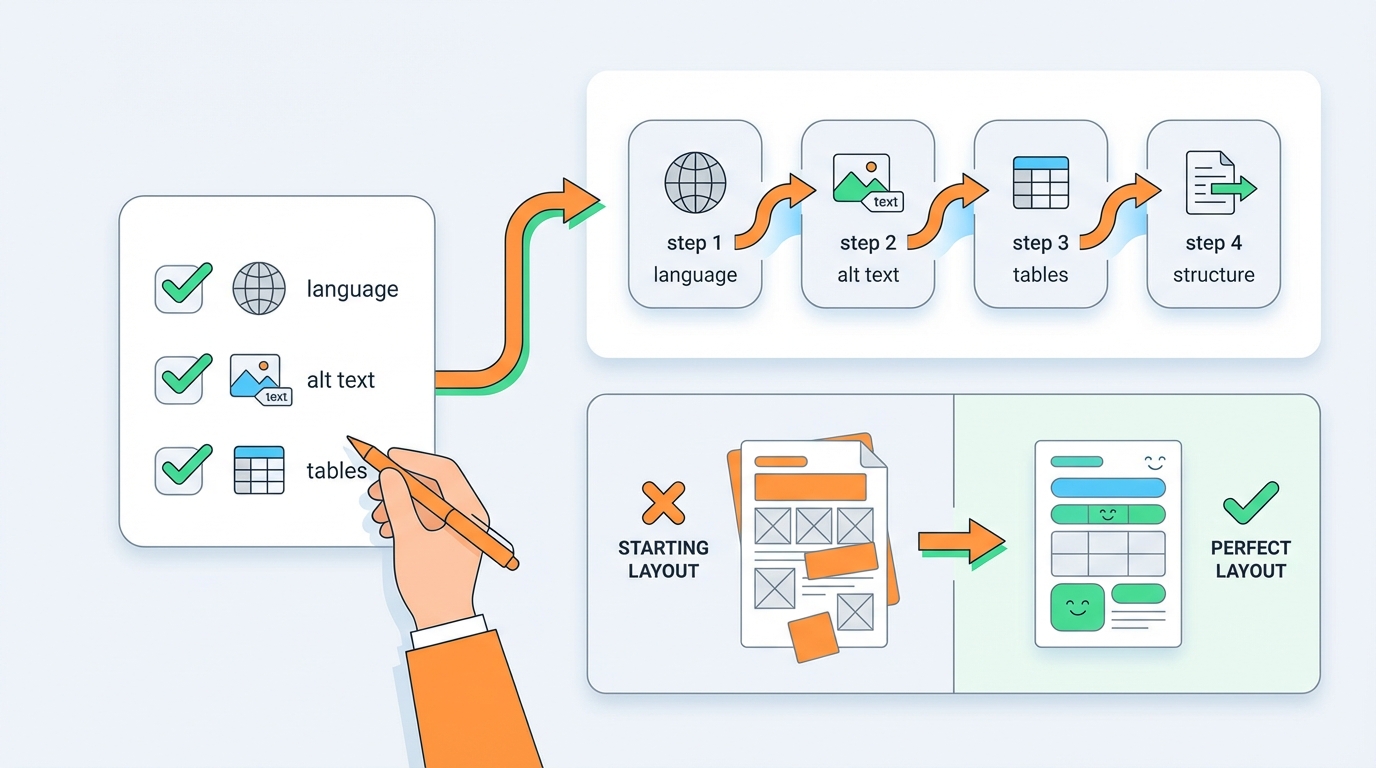
Practical starting point
You don’t have to perfect everything at once. Start with:
- language + title always correct
- an alt-text workflow (even if initially manual)
- tables at least recognized as tables
- veraPDF as a gate on every build
Then iterate on semantics (headings, reading order, artifacts).
How I can help
If your PDF/A-1a or PDF/UA output is “almost compliant” (or keeps breaking after changes), I can help you make it predictable:
- analyze failures (veraPDF/PAC) and pinpoint root causes
- define a tagging strategy from your source (Word/HTML/XML)
- implement quality gates + regression checks in CI/CD
- deliver a pipeline that produces compliant output consistently
Want to spar? Send me a sample PDF + validator output, and I’ll point out the fastest wins.
Does your publishing pipeline still use RenderX XEP?
Read which XEP dependencies, regressions and PDF/UA requirements should be made measurable before migrating to Apache FOP.