Watch the video
Quick version? Watch the video. For full context, read the article.
Many organizations want to “do something with AI” for their service desk. Understandable: ticket volumes keep rising, knowledge is scattered, and first-line questions are often repetitive. But there’s one big catch: a chatbot that’s occasionally wrong is worse than no chatbot at all. The real trick is not “a bigger model,” but a system you can measure, steer, and improve. In this post, I’ll show a practical approach using an emerging pattern from the LLM ecosystem: DSPy + GEPA.
Why standard RAG bots often disappoint
A common setup is RAG: retrieve relevant snippets from your knowledge base (Confluence, SharePoint, runbooks) and let an LLM produce an answer. It works… until it doesn’t. Typical failure modes:
- The bot makes things up when sources are incomplete.
- It produces answers that sound confident but don’t match your actual process.
- It forgets to escalate when risk is involved (security, privacy, production incidents).
- Responses become inconsistent across teams and agents. What you really want is AI that behaves like a strong service desk colleague: grounded, concise, asks for missing info, and knows when to hand over.

The core idea: AI as a program, not a single prompt
This is where DSPy comes in. Instead of one giant prompt, you build your service desk assistant as a pipeline:
-
Classification
Is this an incident, a how-to, an account issue, a change request? -
Retrieval (knowledge search)
Pull the right sources: KB articles, runbooks, policies, known issues. -
Answer generation
Produce a response with:- clear steps
- the right tone (friendly, direct)
- source references (quotes or links)
-
Validation / “confidence gate”
Check whether there is enough evidence in the sources.
If not: ask clarifying questions or escalate.
This may sound straightforward, but it’s a major shift: each step can be tested, improved, and tuned independently.
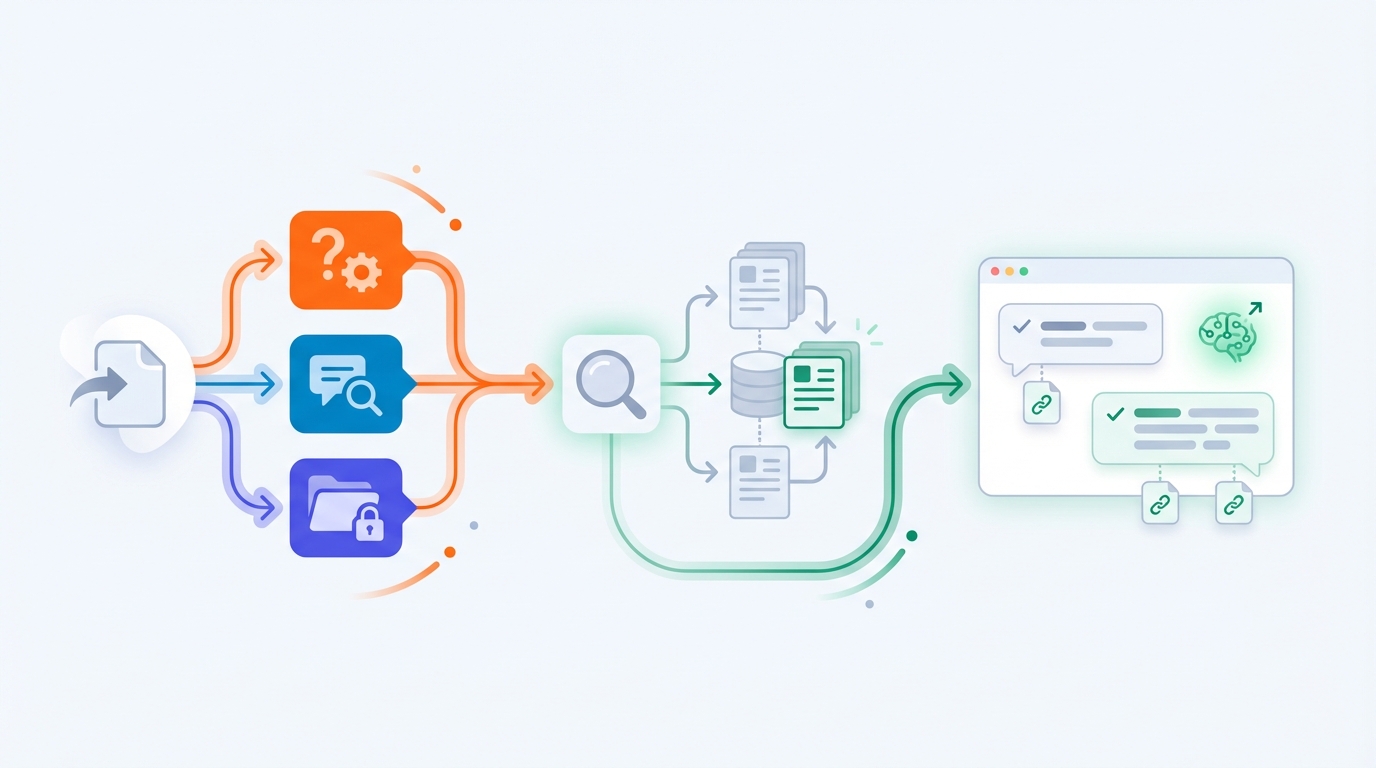
GEPA: automatically improving prompts using real tickets
So how do you make that pipeline actually good?
That’s where GEPA comes in (an optimizer used with DSPy). Instead of manual prompt tweaking:
- Take a set of historical tickets (e.g., 500–2000).
- Define what “good” means: correctness, the right steps, correct escalation, groundedness, tone.
- Let GEPA iterate on prompt/instruction variants across the pipeline.
- Keep what performs best and continue evolving from there.
Think of it as “unit tests for AI behavior,” not for code.
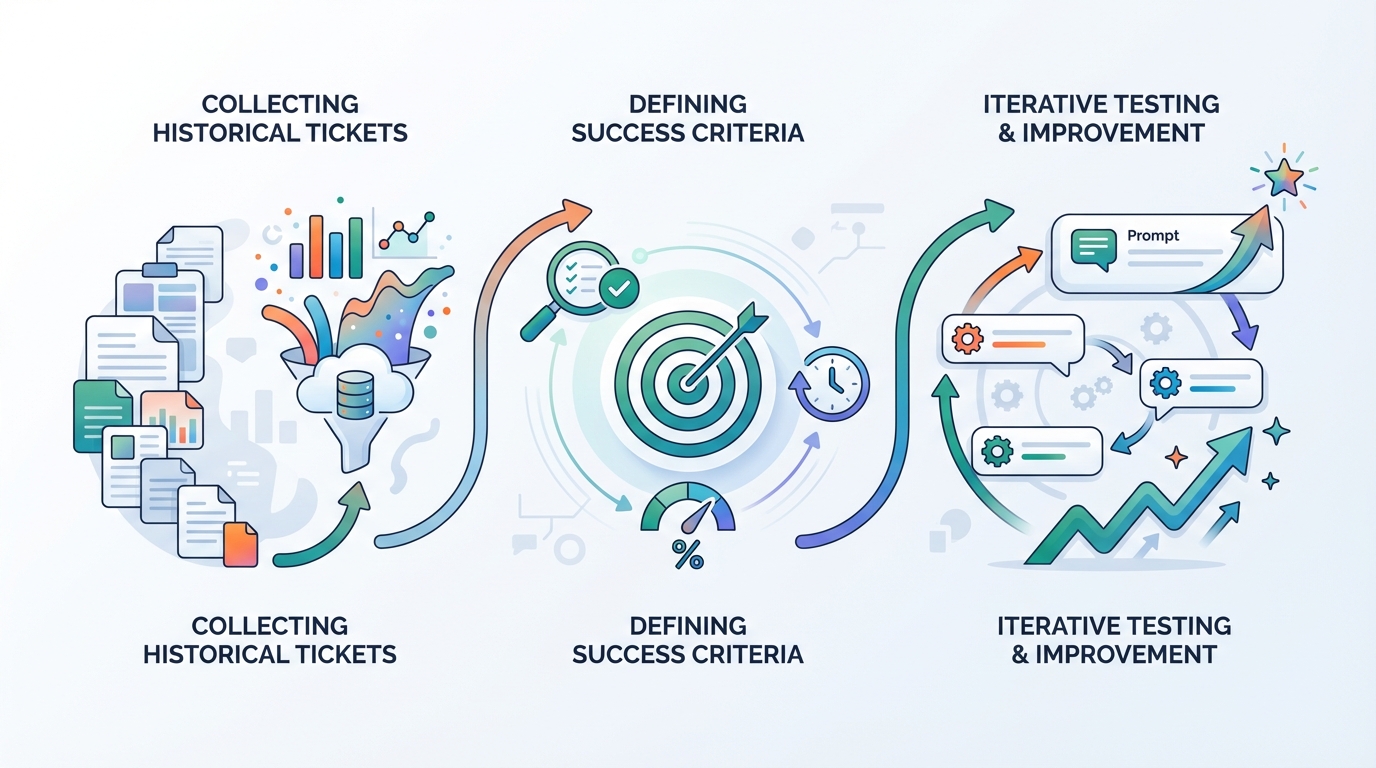
What does a good evaluation metric look like?
This is the most important part. If you only measure “sounds good,” you’ll get a bot that’s persuasive. If you measure what you truly care about, you get reliability.
For service desk answers you can score, for example:
- Correctness (is it factually right?)
- Groundedness (is it supported by sources, or guessed?)
- Escalation behavior (route to humans when uncertain or high-risk)
- Completeness (no missing crucial steps)
- Format & tone (short, actionable bullets, consistent next steps)
Metrics can be partly automated (rules/checks/tests) and partly evaluated by a judge (LLM-as-judge), ideally with periodic human spot checks.
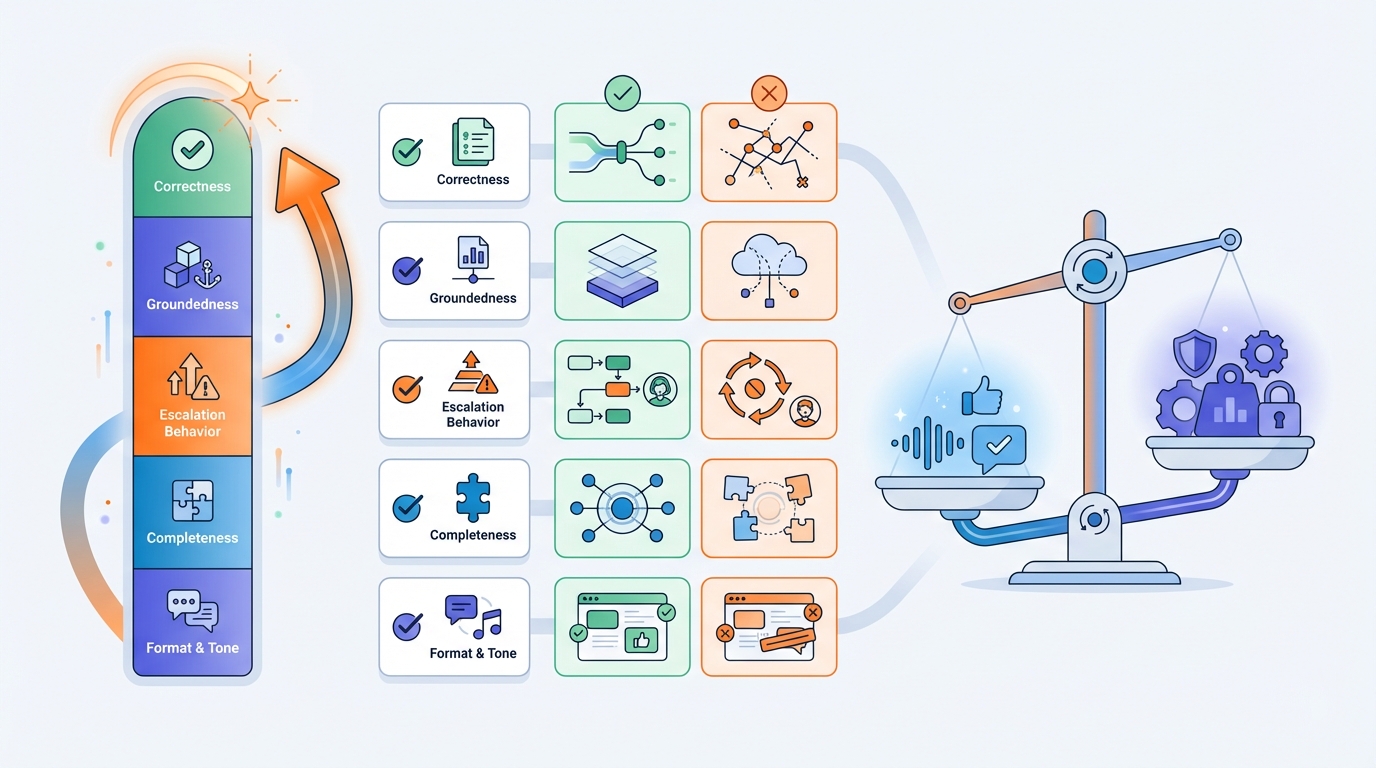
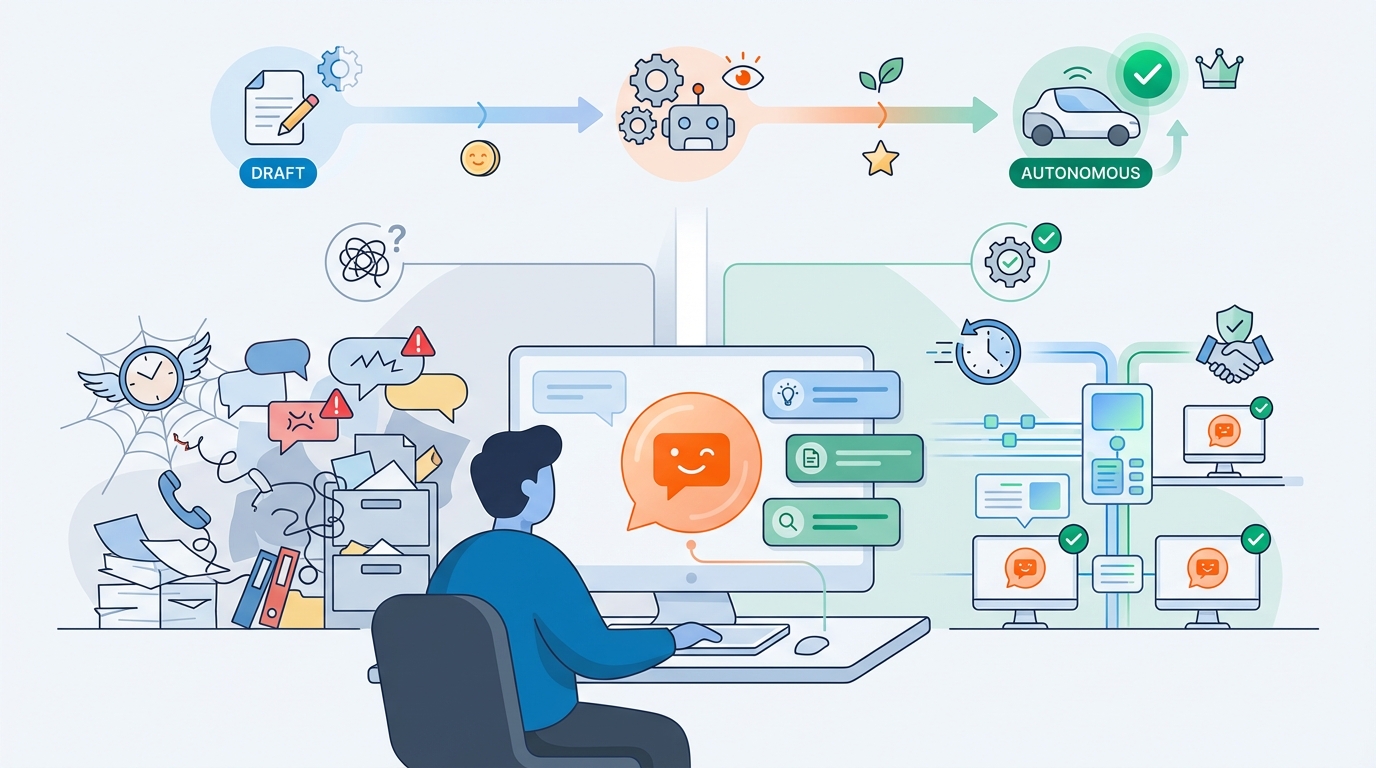
The safe rollout: “draft mode” first, autonomy later
A smart rollout path is to start with an assistant that:
- produces draft replies for agents,
- attaches the relevant KB sources,
- and explains “why” (citations + confidence).
This already delivers big wins: faster replies, less searching, more consistency—without going fully autonomous immediately.
Once evaluations are stable, you can gradually expand to partial or full autonomy.
What you need to make this work
In practice, these are the building blocks:
-
A “source of truth” knowledge base
Confluence/SharePoint/Markdown/PDF/runbooks (ideally curated and maintained). -
Historical tickets
For training/evaluation. (Often needs anonymization/redaction for privacy.) -
Clear policies and guardrails
What is the bot allowed to do? When must it escalate? -
An evaluation loop
Re-run the same test set regularly to catch regressions (CI/CD for AI behavior).
When it’s especially worth it
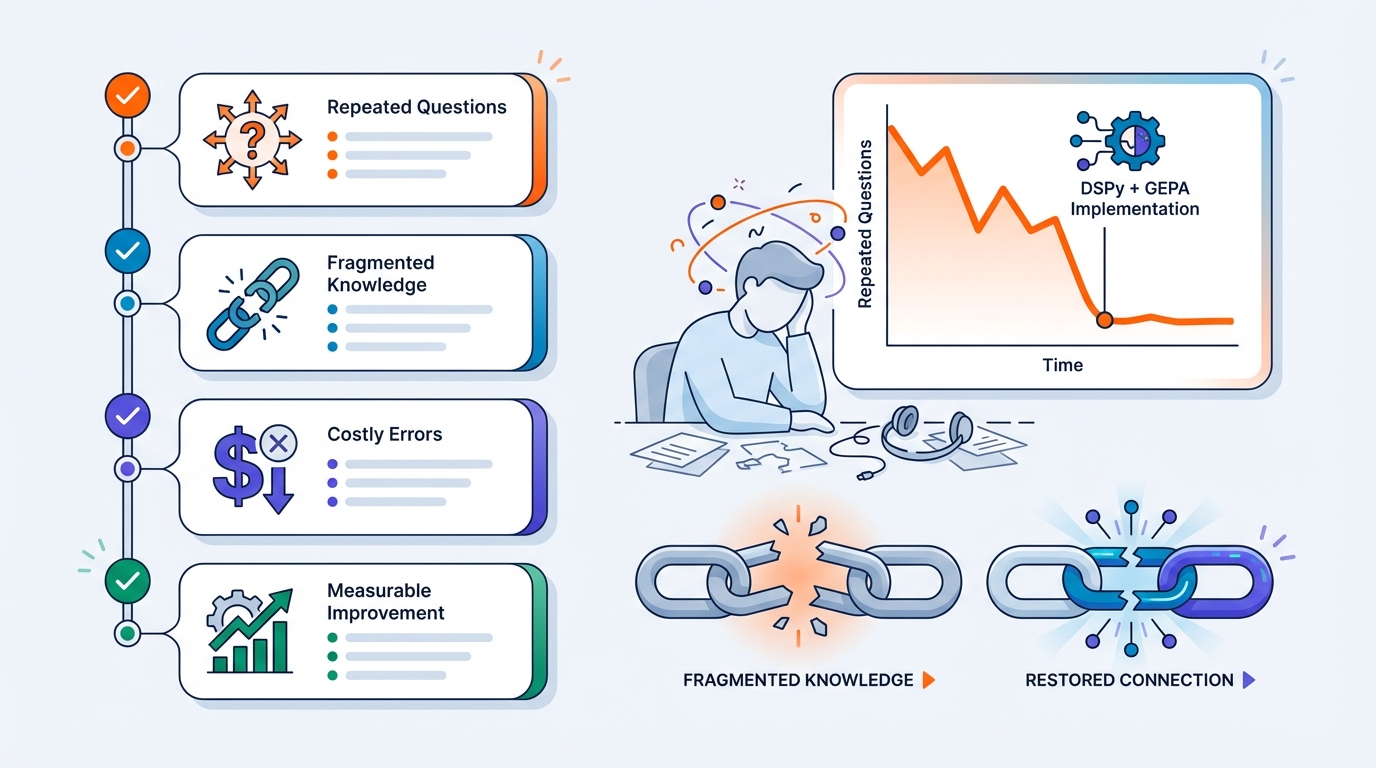
DSPy + GEPA is a strong fit when:
- you have many repetitive tickets,
- knowledge is fragmented,
- mistakes are costly (security, privacy, production),
- and you want measurable improvement—not just vibes.
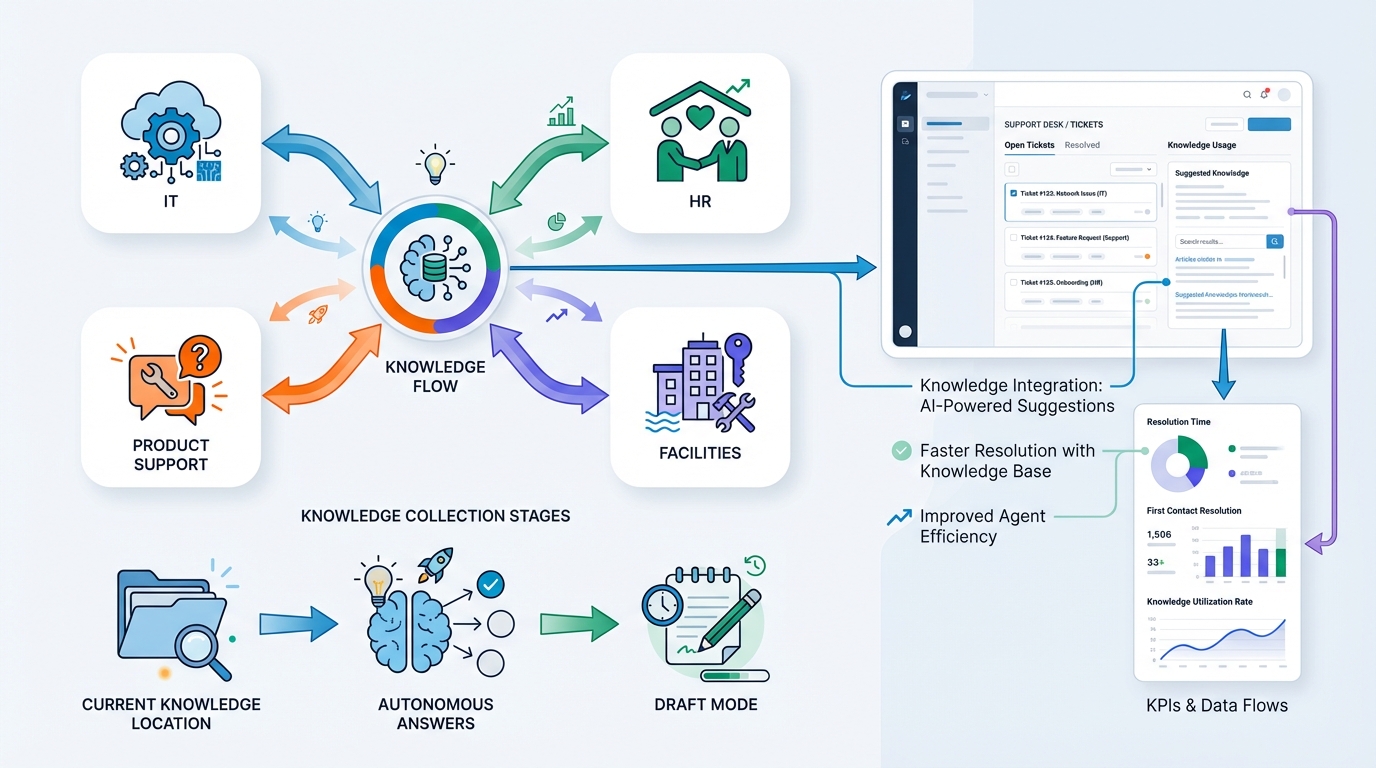
Want to apply this to your service desk?
If you tell me:
- the domain (IT, product support, HR, facilities),
- where your knowledge currently lives,
- and whether you want autonomous answers or “draft mode” first,
I can outline a concrete plan: pipeline design, dataset setup, evaluation metrics, and how to integrate with your ticketing system (Zendesk/Jira/ServiceNow/Teams).