Bekijk de video
Even snel de kern? Bekijk de video. Voor de volledige context: lees het artikel.
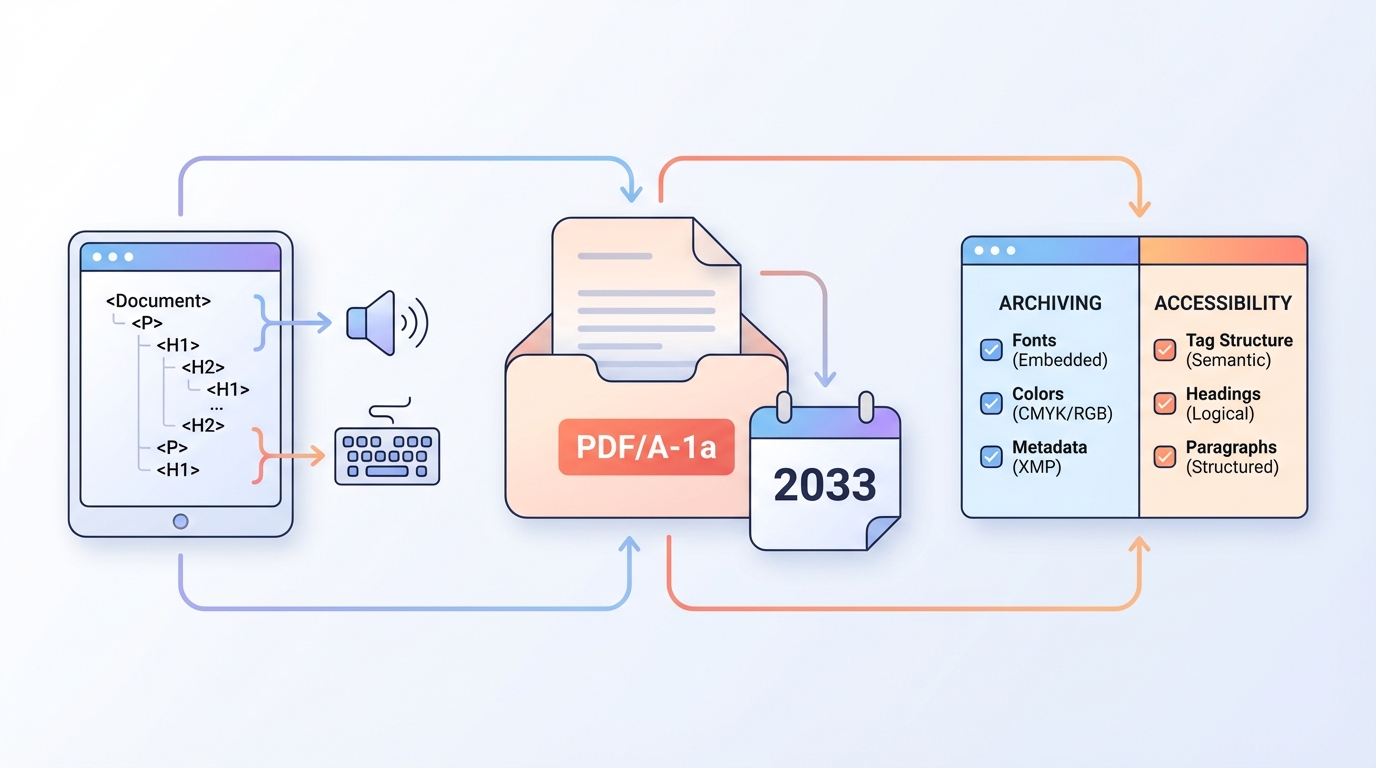
PDF is vaak het eindstation van je keten: wat je publiceert, moet lang houdbaar (archivering) én toegankelijk (leesbaar voor iedereen) zijn.
En precies daar gaat het vaak mis: PDF/A-1a en PDF/UA klinken als vinkjes, maar blijken een stapel concrete eisen die je pipeline kan laten omvallen.
In dit artikel leg ik uit waar teams op vastlopen en hoe je dit zo inricht dat het voorspelbaar wordt.
Waarom dit zo vaak misgaat
Veel teams doen “iets met PDF” aan het einde van een traject. Ergens exporteren ze een Word/HTML, of genereren ze een PDF via een library. Het werkt… tot het moet voldoen aan:
- PDF/A-1a (archiefkwaliteit, consistent reproduceerbaar)
- PDF/UA (toegankelijkheid: tags, structuur, alt-teksten, leesvolgorde)
- én soms ook extra eisen vanuit ketens/overheden/portalen Dan komen de verrassingen:
- “veraPDF faalt opeens na een kleine wijziging.”
- “De PDF is visueel prima, maar screenreaders struikelen.”
- “Metadata klopt niet, fonts niet embedded, tags incompleet.”

PDF/A-1a vs PDF/UA in normale-mensen-taal
PDF/A-1a (archivering)
Doel: over 10+ jaar nog exact hetzelfde document kunnen openen en reproduceren.
Typische eisen waar je tegenaan loopt:
- fonts moeten goed/volledig embedded zijn
- kleuren/profiles moeten kloppen
- metadata (XMP) moet consistent zijn
- geen “verborgen afhankelijkheden” (denk aan externe content)
PDF/UA (toegankelijkheid)
Doel: een PDF die logisch te lezen is door assistive tech.
Typische eisen:
- correcte tag-structuur (headings, paragrafen, lijsten)
- correcte leesvolgorde
- alt-tekst bij afbeeldingen
- tabellen moeten als tabel herkenbaar zijn (TH/TD, scope/headers)
- documenttaal en titel correct ingesteld
In de praktijk: PDF/A is “document als archiefobject”, PDF/UA is “document als semantische structuur”.
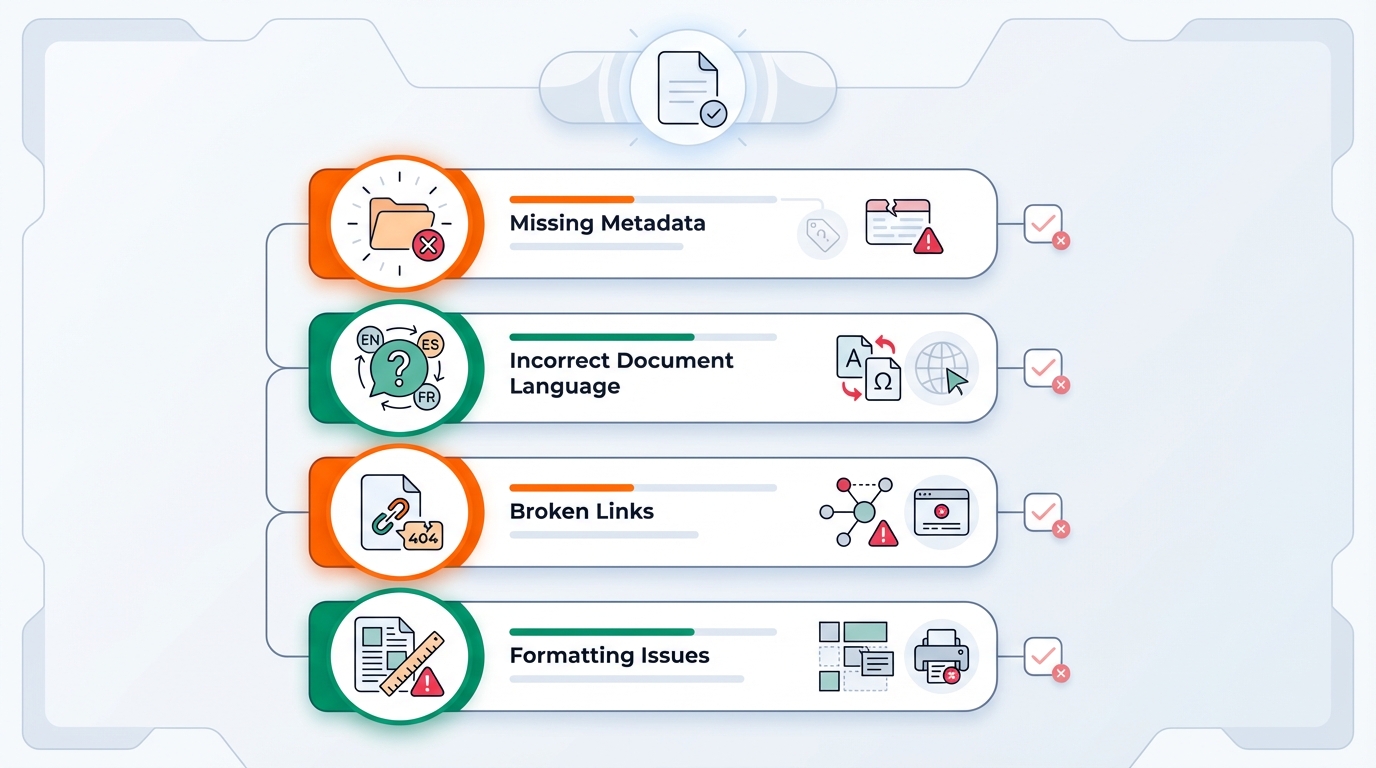
Waar het het vaakst misgaat (de top 10)
- XMP metadata: titel/author/producer inconsistent of ontbrekend
- Document language ontbreekt of staat verkeerd
- Title niet ingesteld (of niet “displayed”)
- Fonts niet (volledig) embedded
- Afbeeldingen zonder alt-tekst, of decoratief maar niet als artifact gemarkeerd
- Heading levels slaan stappen over (H1 → H3)
- Leesvolgorde klopt visueel wel, maar logisch niet
- Tabellen: geen echte headers / scope verkeerd
- Links zonder duidelijke link-tekst (alleen “klik hier”)
- Generator/export produceert “bijna tags”, maar net niet conform
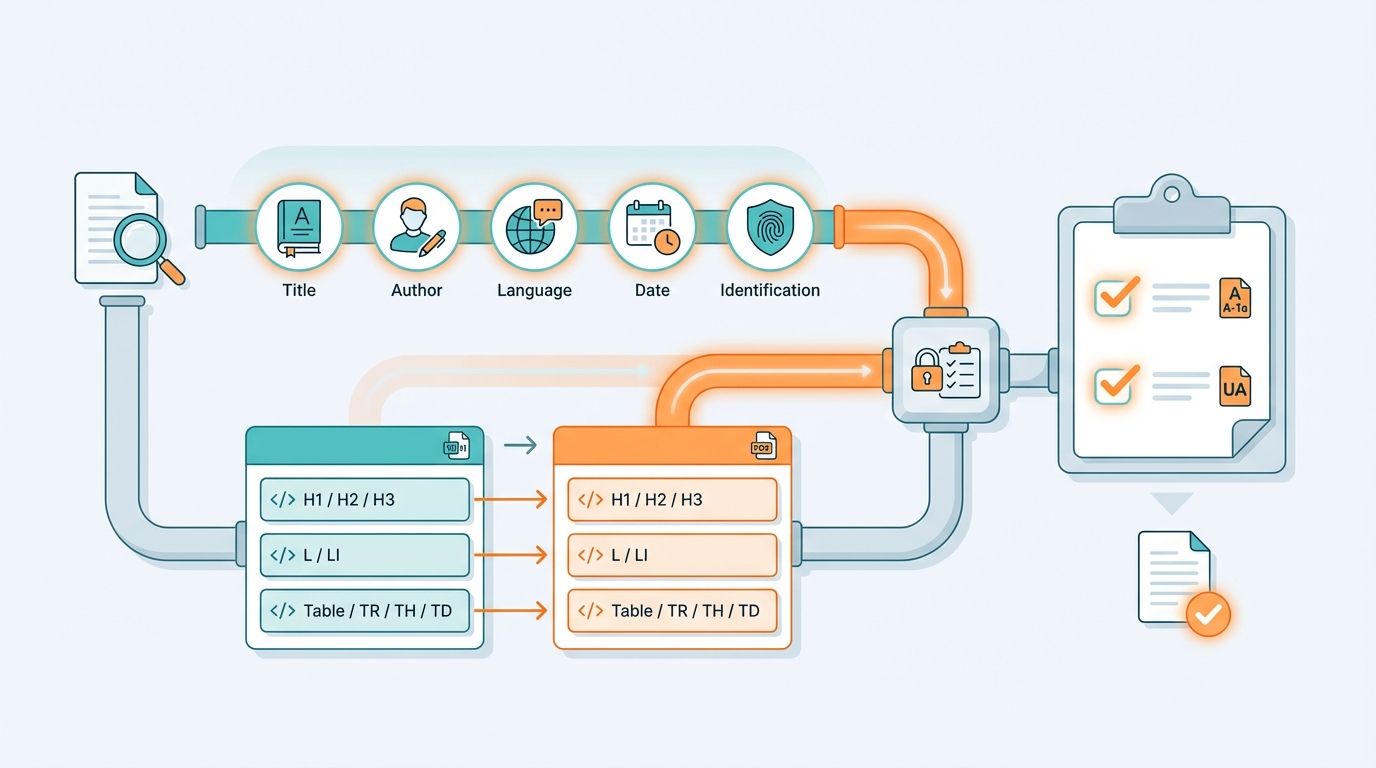
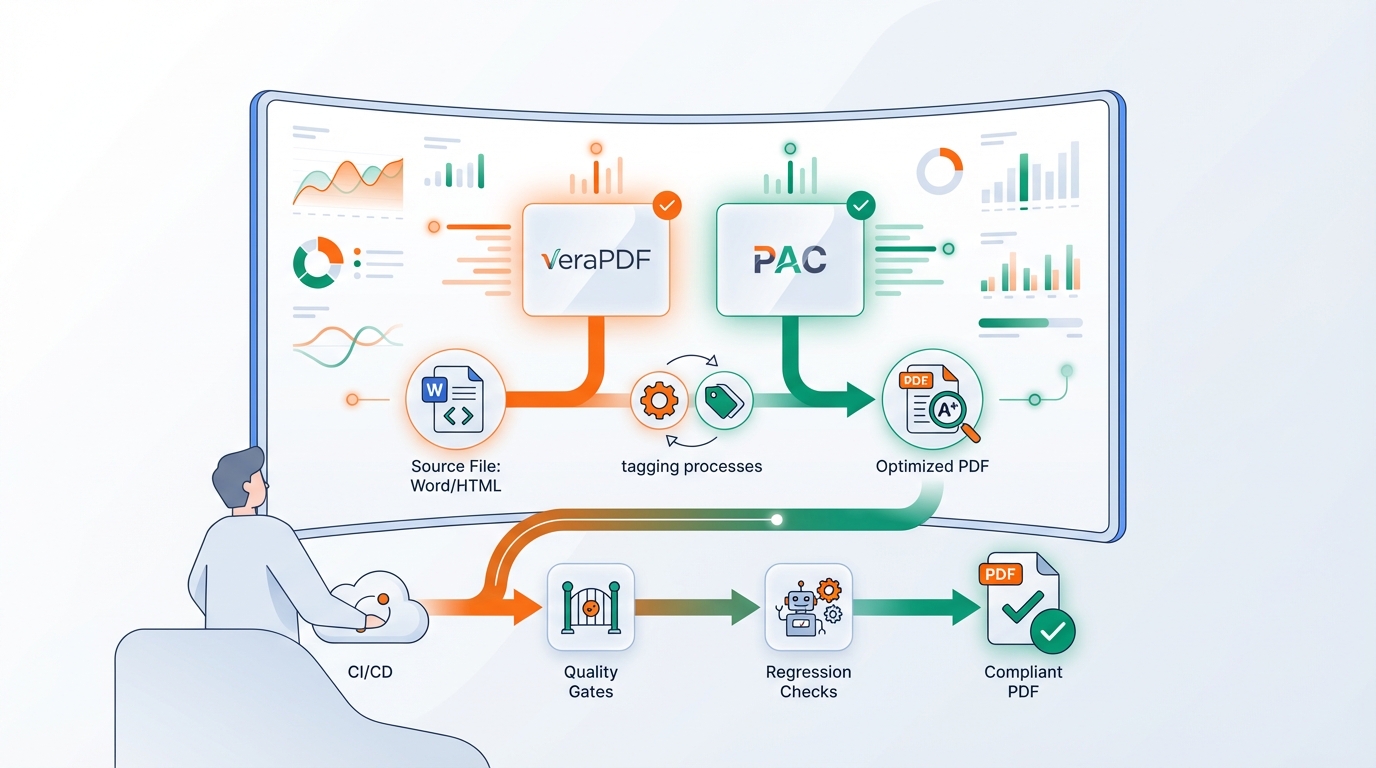
De oplossing: maak er een gecontroleerde keten van
De truc is: behandel PDF/A-1a en PDF/UA niet als “export”, maar als een kwaliteitsdrempel in je pipeline.
1) Eén bron van waarheid voor metadata
Leg vast waar titel, auteur, taal, datum en identificaties vandaan komen.
En zet dat in je keten als “verplicht”, net als een schema/validatie op XML.
2) Tagging is geen bijvangst
Als je uit Word/HTML komt: definieer mappingregels:
- heading styles → H1/H2/H3
- lijsten → L/LI
- tabellen → Table/TR/TH/TD
- afbeeldingen → Figure + alt-tekst, of Artifact
3) Quality gates: valideren vóór je publiceert
Gebruik validators als gate, niet als “achteraf diagnose”:
- veraPDF voor PDF/A (en deels PDF/UA checks)
- een PDF/UA checker (bijv. PAC) voor toegankelijkheid
- voeg eigen checks toe (bijv. ontbrekende alt-teksten, taal, title)
4) Maak fouten reproduceerbaar
Als een PDF faalt, wil je:
- de exacte validator output opslaan
- de broninput + versie opslaan
- een “diff” kunnen doen: wat veranderde er in generator/stylesheet?
Dat scheelt je enorm veel tijd bij “onverklaarbare” regressies.
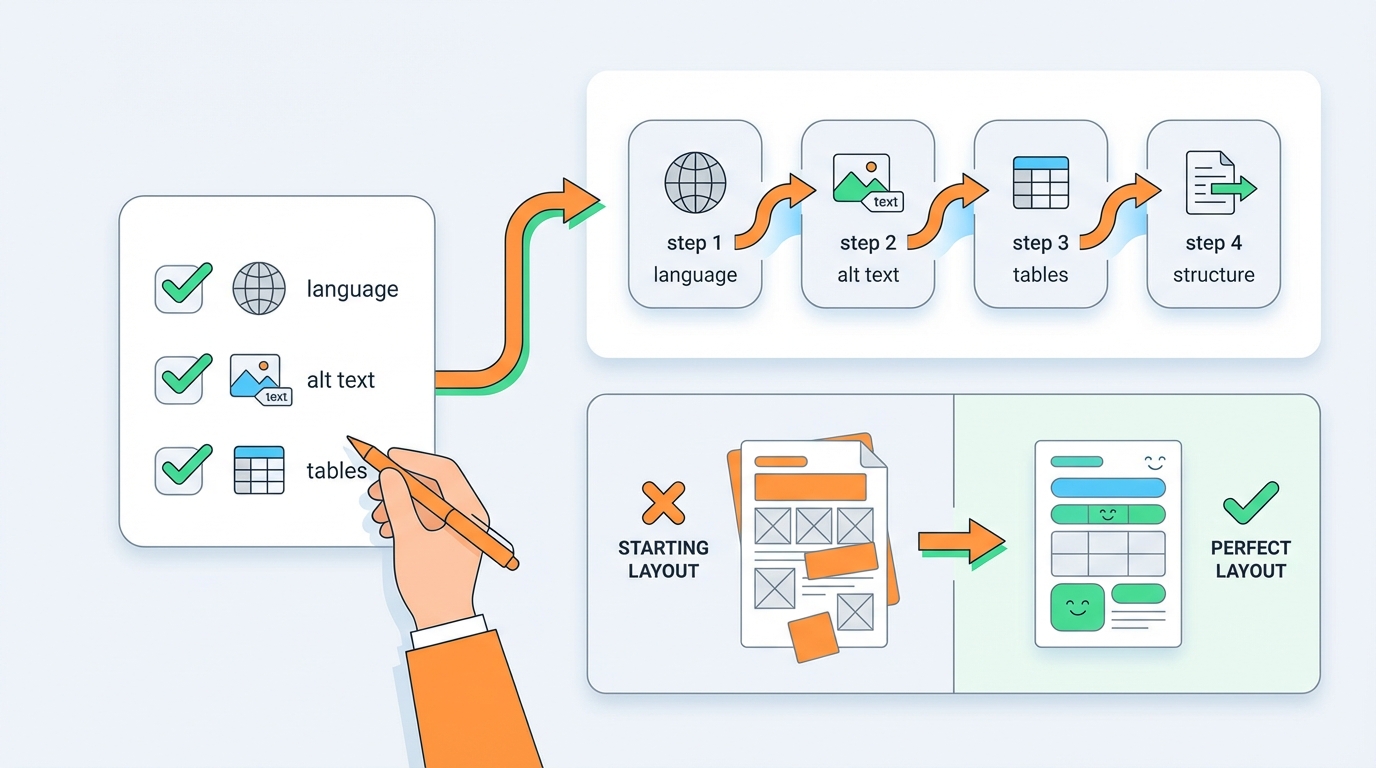
Praktische aanpak: klein beginnen
Je hoeft niet alles in één keer perfect te maken. Start met dit minimum:
- documenttaal + titel altijd correct
- alt-tekst pipeline (ook al is het eerst handmatig)
- tabellen minimaal herkenbaar als tabel
- veraPDF gate op elke build
Daarna pas je de semantiek verder aan (headings, leesvolgorde, artifacts).
Wat ik voor je kan doen
Als je PDF/A-1a of PDF/UA nu “net niet” is (of steeds breekt na wijzigingen), dan help ik je dit structureel oplossen:
- analyse van failures (veraPDF/PAC) en herleidbare oorzaak
- mapping-strategie voor tagging vanuit jouw bron (Word/HTML/XML)
- quality gates + regression checks in CI/CD
- een pipeline die voorspelbaar compliant output levert
Wil je sparren over jouw situatie? Stuur me een voorbeeld-PDF + validator output, dan kijk ik mee waar de snelste winst zit.
Werkt uw publicatieketen nog met RenderX XEP?
Lees dan welke XEP-afhankelijkheden, regressies en PDF/UA-eisen u vóór een migratie naar Apache FOP meetbaar moet maken.