Bekijk de video
Even snel de kern? Bekijk de video. Voor de volledige context: lees het artikel.
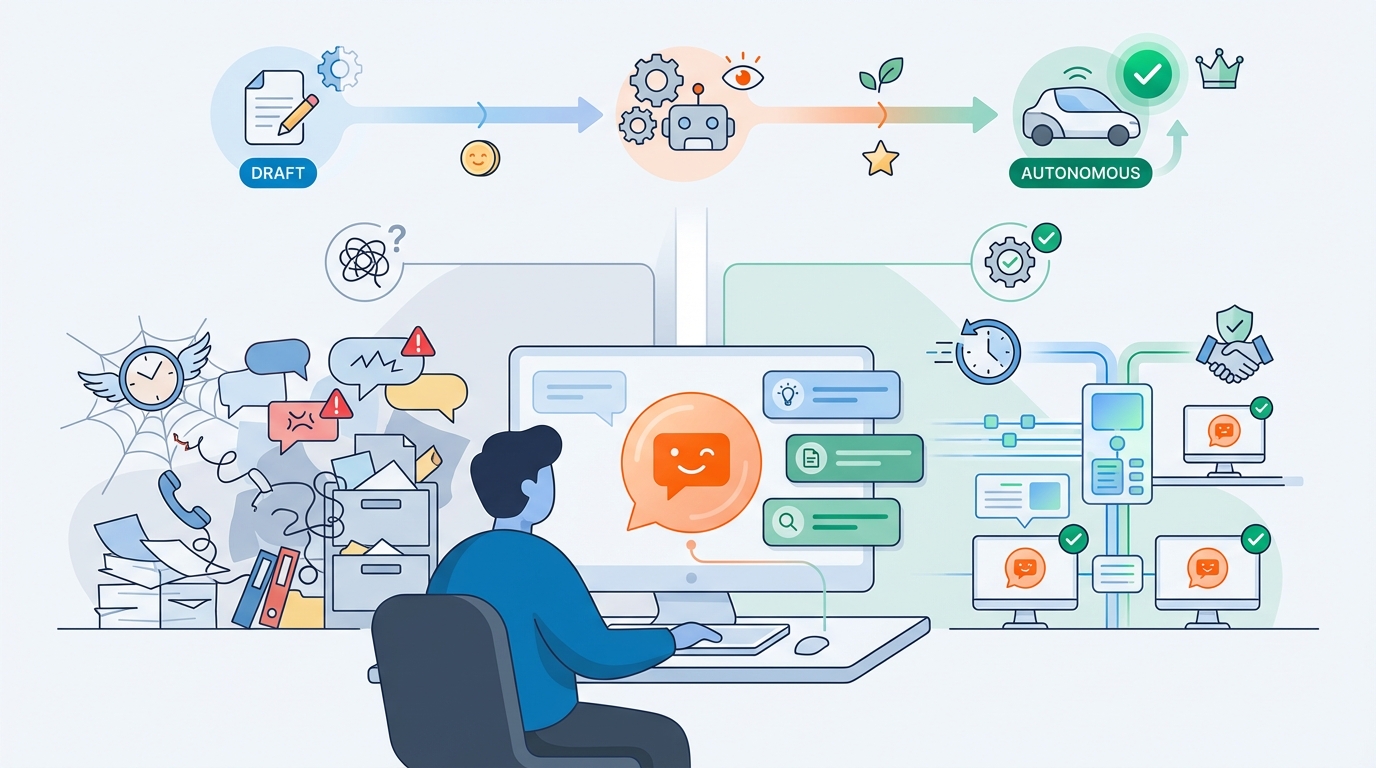
Veel organisaties willen “iets met AI” op de servicedesk. Logisch: tickets stapelen zich op, kennis zit verspreid, en de eerste-lijns vragen zijn vaak herhaling. Maar er is één probleem: een chatbot die soms onzin uitkraamt is erger dan geen chatbot. De truc is daarom niet “een groter model”, maar: een systeem dat je kunt meten, bijsturen en verbeteren. In deze post laat ik zien hoe je dat aanpakt met een aanpak uit de LLM-wereld: DSPy + GEPA.
Waarom standaard RAG-bots vaak tegenvallen
Een klassieke opzet is RAG: je zoekt relevante stukken uit je kennisbank (Confluence, SharePoint, runbooks) en laat een LLM daar een antwoord van maken. Dat werkt… totdat het niet werkt. Veel voorkomende issues:
- De bot verzint details als de bron onvoldoende is.
- Hij geeft een antwoord dat “lekker klinkt”, maar niet past bij jullie processen.
- Hij vergeet te escaleren bij risico (security, privacy, productie-incidenten).
- Antwoorden zijn inconsistent tussen medewerkers/teams. Wat je eigenlijk wil is: AI die zich gedraagt als een goede servicedesk-collega: bronvast, kort, vraagt door als informatie ontbreekt, en weet wanneer hij moet doorschakelen.

De kern: AI als programma in plaats van één prompt
Hier komt DSPy in beeld. In plaats van één grote prompt bouw je je servicedesk-assistent als een pipeline:
-
Classificatie
Is dit een storing, een how-to, een accountvraag, een wijzigingsverzoek? -
Retrieval (zoeken in kennis)
Zoek de juiste stukken: KB-artikelen, runbooks, policy’s, bekende issues. -
Antwoord genereren
Schrijf een antwoord met:- duidelijke stappen
- nette toon (“jij”)
- bronverwijzingen (citaten of links)
-
Controle / “confidence gate”
Check: is er genoeg bewijs in de bronnen?
Zo niet: stel gerichte vragen of escaleren.
Dit klinkt simpel, maar het verschil is groot: je kunt elke stap apart verbeteren, meten en finetunen.
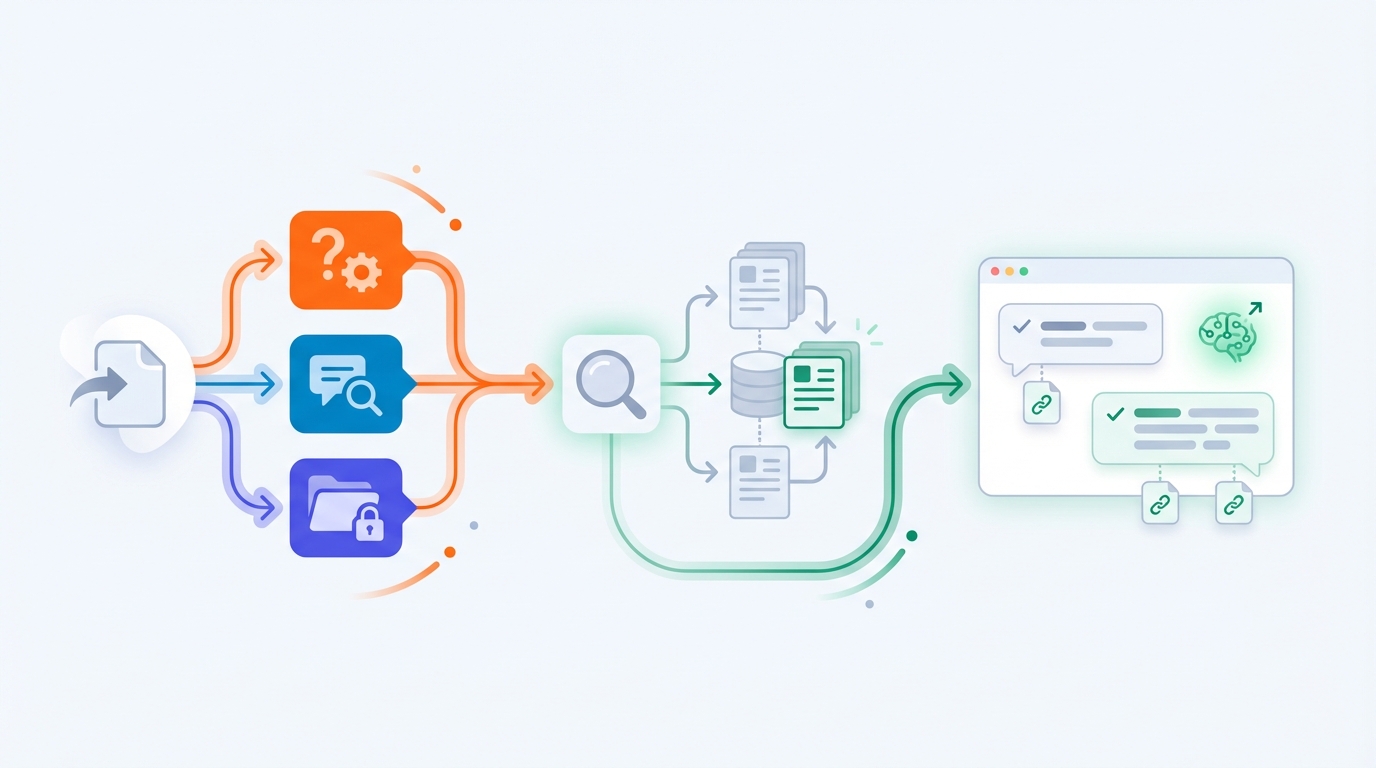
GEPA: automatisch betere prompts op basis van echte tickets
Oké, maar hoe maak je die pipeline dan écht goed?
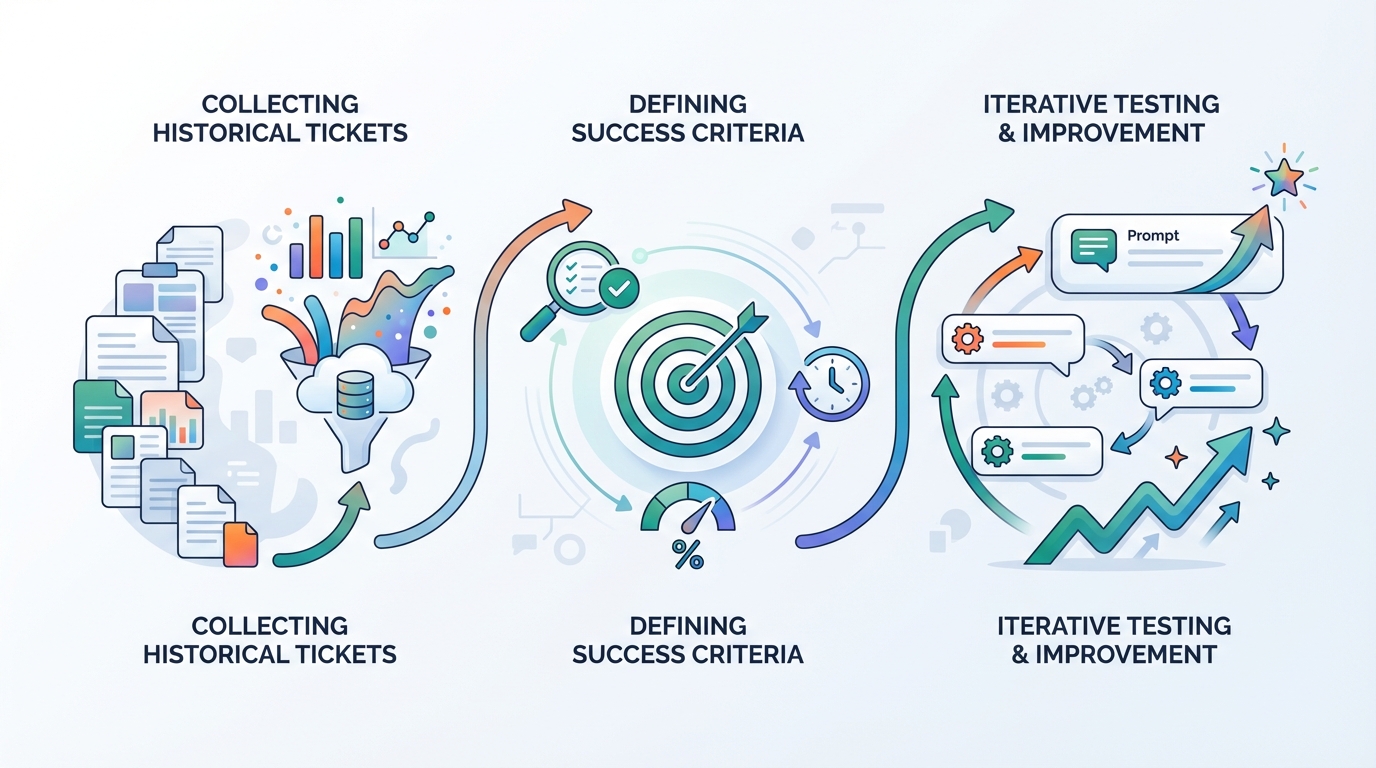
Daar komt GEPA bij (een optimizer die bij DSPy hoort). In plaats van handmatig prompt-tweaken doe je dit:
- Je pakt een set historische tickets (bijv. 500–2000 stuks).
- Je definieert wat “goed” is: correcte oplossing, juiste stappen, juiste escalatie, bronvast, juiste tone-of-voice.
- Je laat GEPA iteratief varianten van je prompts/instructies proberen.
- GEPA kiest wat beter werkt en bouwt daarop door.
Zie het als “unit tests” voor je AI: niet op code, maar op gedrag.
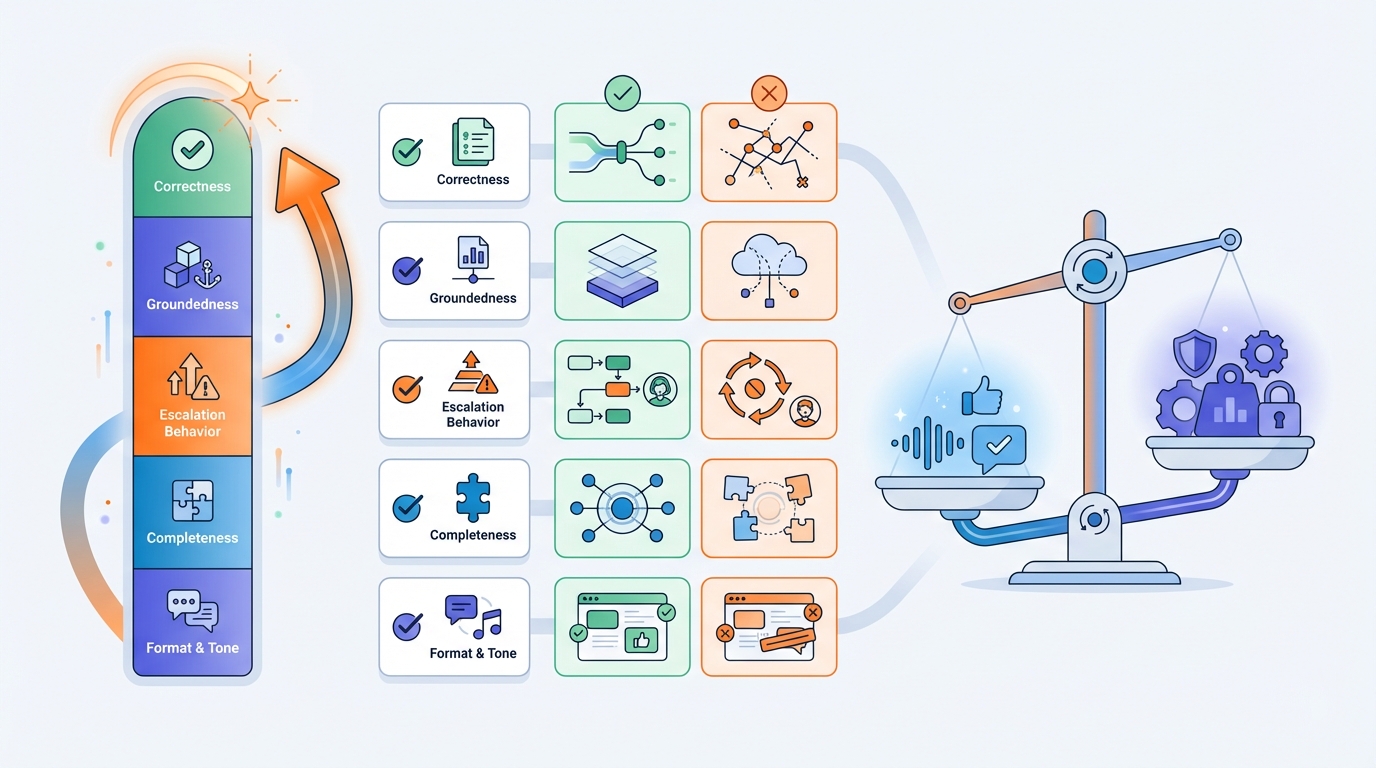
Wat is een goede meetlat (metric)?
Dit is het belangrijkste stuk. Als je alleen “klinkt goed” meet, krijg je een bot die overtuigend praat. Als je meet op wat je echt wil, krijg je betrouwbaarheid.
Voor servicedesk-antwoorden kun je o.a. scoren op:
- Correctheid (klopt het inhoudelijk?)
- Groundedness (komt het uit de bron, of wordt er gegokt?)
- Escalatiegedrag (bij onzekerheid of risico: doorsturen)
- Compleetheid (mist er een cruciale stap?)
- Format & tone (“jij”, kort, bullets, duidelijke next steps)
Die metric kun je deels automatiseren (checks, regels, tests) en deels met “judge” evaluatie (LLM-as-judge), idealiter met steekproefsgewijze menselijke controle.
Het veilige pad: eerst “draft mode”, dan autonoom
Een slimme route is om te starten met een assistent die:
- conceptantwoorden maakt voor servicedesk-medewerkers,
- relevante KB-stukken erbij zet,
- en aangeeft “waarom” (broncitaten + confidence).
Dat levert vaak al veel winst op: sneller antwoorden, minder zoekwerk, meer consistentie — zonder dat je direct alles autonoom laat gaan.
Pas als de evaluaties stabiel zijn, kun je voorzichtig opschalen naar (deels) autonoom antwoorden.
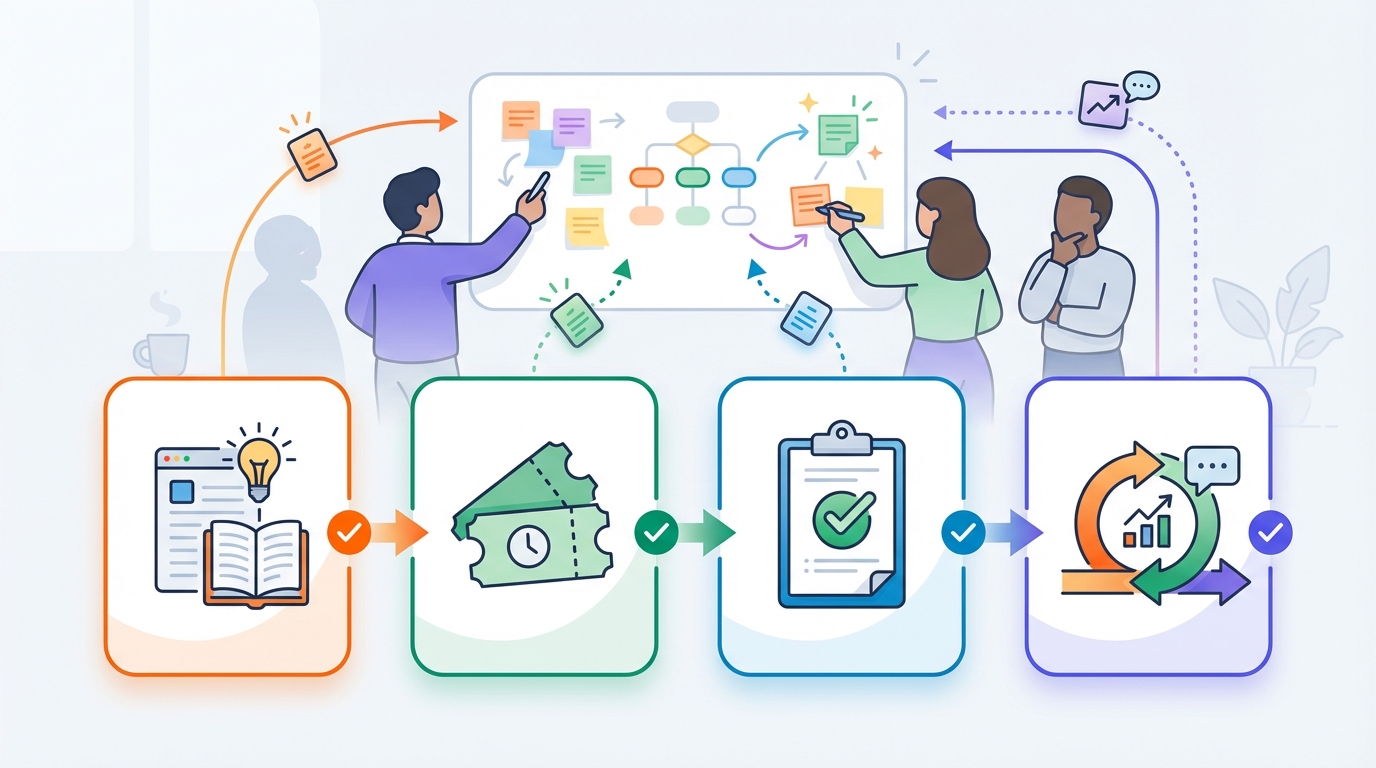
Wat je nodig hebt om dit te laten slagen
In de praktijk zijn dit de bouwstenen:
-
Kennisbron als ‘single source of truth’
Confluence/SharePoint/Markdown/PDF/runbooks (liefst goed vindbaar en onderhouden). -
Historische tickets
Voor training/evaluatie. (Vaak moeten die eerst opgeschoond/anoniem gemaakt worden i.v.m. AVG.) -
Heldere policies
Wat mag de bot wel/niet doen? Welke situaties moeten altijd escaleren? -
Een evaluatie-lus
Regelmatig meten op een vaste set tickets zodat je regressies ziet (zoals CI/CD voor AI).
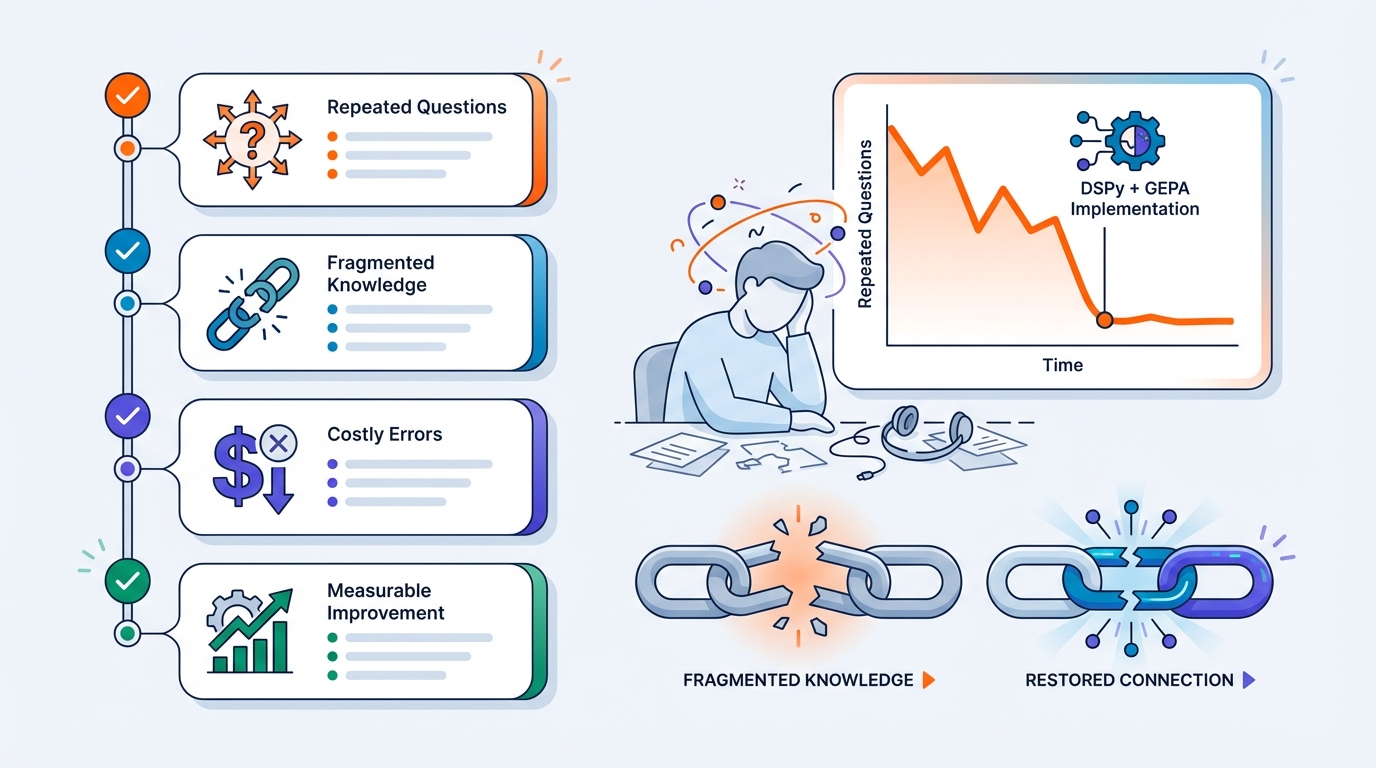
Wanneer dit vooral de moeite waard is
DSPy + GEPA is vooral interessant als:
- je servicedesk veel herhaalvragen krijgt,
- kennis versnipperd is,
- fouten duur zijn (security, privacy, productie),
- en je niet wilt vertrouwen op “het voelt beter”, maar op meetbare verbetering.
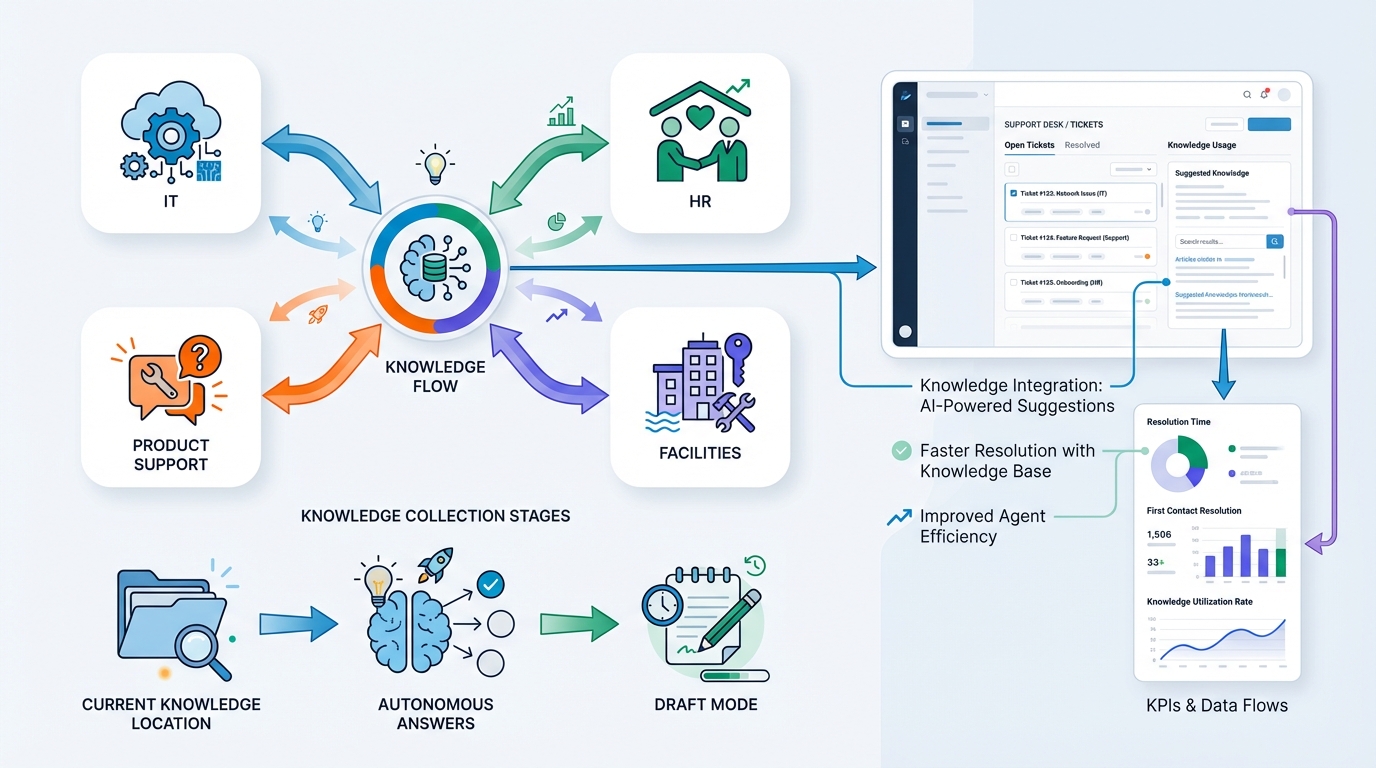
Wil je dit toepassen op jouw servicedesk?
Als je me vertelt:
- welk domein (IT, product support, HR, facilitaire dienst),
- waar de kennis nu zit,
- en of je autonoom wil antwoorden of eerst “draft mode”,
dan kan ik een concreet plan schetsen: pipeline, dataset-opzet, metrics, én hoe je dit koppelt aan jullie ticketing (bijv. Zendesk/Jira/ServiceNow/Teams).