Bekijk de video
Even snel de kern? Bekijk de video. Voor de volledige context: lees het artikel.
Veel organisaties hebben honderden (of duizenden) PDF’s op hun website staan die niet voldoen aan PDF/UA (ISO 14289). Dat lijkt een technisch detail, maar in de praktijk raakt het direct aan wettelijke toegankelijkheidseisen, én aan de bruikbaarheid van je informatie voor iedereen (screenreaders, toetsenbordnavigatie, hergebruik van tekst). In deze post lees je:
- wat PDF/UA precies is en waarom je huidige PDF’s vaak falen,
- hoe de Europese verplichtingen rond digitale toegankelijkheid hierop landen,
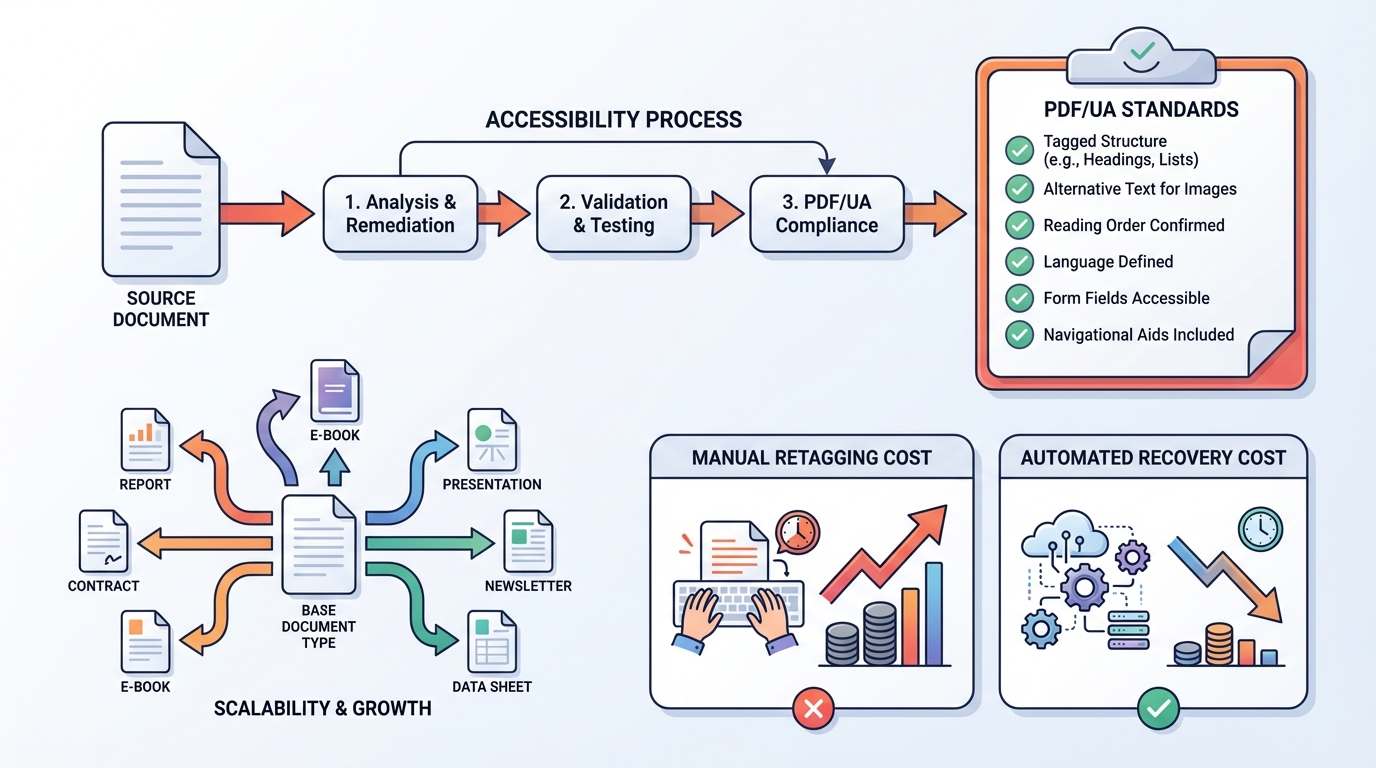
- en hoe Elk Solutions dit geautomatiseerd oplost: analyseren → groeperen → reconstrueren → regenereren → valideren met veraPDF.
1) Waarom je huidige PDF’s vaak “niet toegankelijk” zijn
Een PDF kan er visueel perfect uitzien, maar tóch ontoegankelijk zijn. Typische oorzaken:
- Geen tags (Tagged PDF) → screenreaders weten niet wat koppen, alinea’s, lijsten en tabellen zijn.
- Verkeerde leesvolgorde → multi-column layouts, tekstkaders, voetnoten, headers/footers lopen door elkaar.
- Afbeeldingen zonder alternatieve tekst → belangrijke informatie ontbreekt voor assistive tech.
- Tabellen zonder headers/scope → relaties tussen rij/kolomkoppen en cellen zijn onduidelijk.
- Onbetrouwbare tekstextractie → fonts/encodings missen correcte Unicode mapping.
- Documenttaal ontbreekt → screenreaders kunnen niet goed schakelen tussen talen.

2) Is dit een wettelijke vereiste in Europa?
Europa schrijft meestal niet “PDF/UA” voor als verplicht bestandsformaat, maar wél toegankelijkheid van digitale informatie.
Publieke sector: Web Accessibility Directive (EU 2016/2102)
Voor websites en apps van publieke sector organisaties geldt de verplichting om toegankelijk te zijn (inclusief documenten die je aanbiedt). De richtlijn verwijst naar een Europese standaard voor de technische invulling: EN 301 549.
Bron: Directive (EU) 2016/2102 en EN 301 549.
- https://eur-lex.europa.eu/eli/dir/2016/2102/oj/eng
- https://www.etsi.org/deliver/etsi_en/301500_301599/301549/03.02.01_60/en_301549v030201p.pdf
Breder (afhankelijk van scope): European Accessibility Act (EU 2019/882)
De European Accessibility Act breidt toegankelijkheidseisen uit naar een reeks producten en diensten (met nationale implementatie), met toepassing vanaf 28 juni 2025.
Praktisch gevolg: als je PDF’s publiceert die deel zijn van je digitale dienstverlening of publieke informatievoorziening, moet je er rekening mee houden dat ze toegankelijk moeten zijn. PDF/UA is de meest gebruikte norm om “toegankelijke PDF” concreet te maken, omdat hij precies definieert wat er in een PDF nodig is voor assistive technology.
3) Wat is PDF/UA precies?
PDF/UA (Universal Accessibility) is de ISO-standaard ISO 14289-1 voor toegankelijke PDF’s.
Het doel is dat een PDF:
- semantisch is (koppen, paragrafen, lijsten, tabellen, figuren),
- navigatie ondersteunt (leesvolgorde, bookmarks waar relevant),
- tekst betrouwbaar uit te lezen is (Unicode mapping),
- en de juiste “accessibility hooks” bevat (zoals alt-tekst, documenttaal, tabelheaders).
Handige startpunten:
- ISO 14289-1:2014 info: https://www.iso.org/standard/64599.html
- PDF Association overzicht: https://pdfa.org/resource/iso-14289-pdfua/
4) Waarom “even omzetten” vaak niet werkt
Veel tools beloven: “Make accessible” of “Auto-tag”. In de praktijk faalt dat vaak omdat:
- de bron-PDF geen semantiek bevat (de tool moet gokken),
- tabellen/kolommen/footers verkeerd worden geïnterpreteerd,
- en “tags die technisch bestaan” nog niet betekenen dat de inhoud logisch klopt.
Daarom werkt onze aanpak anders: we reconstrueren het document expliciet op basis van een contentmodel per documenttype.
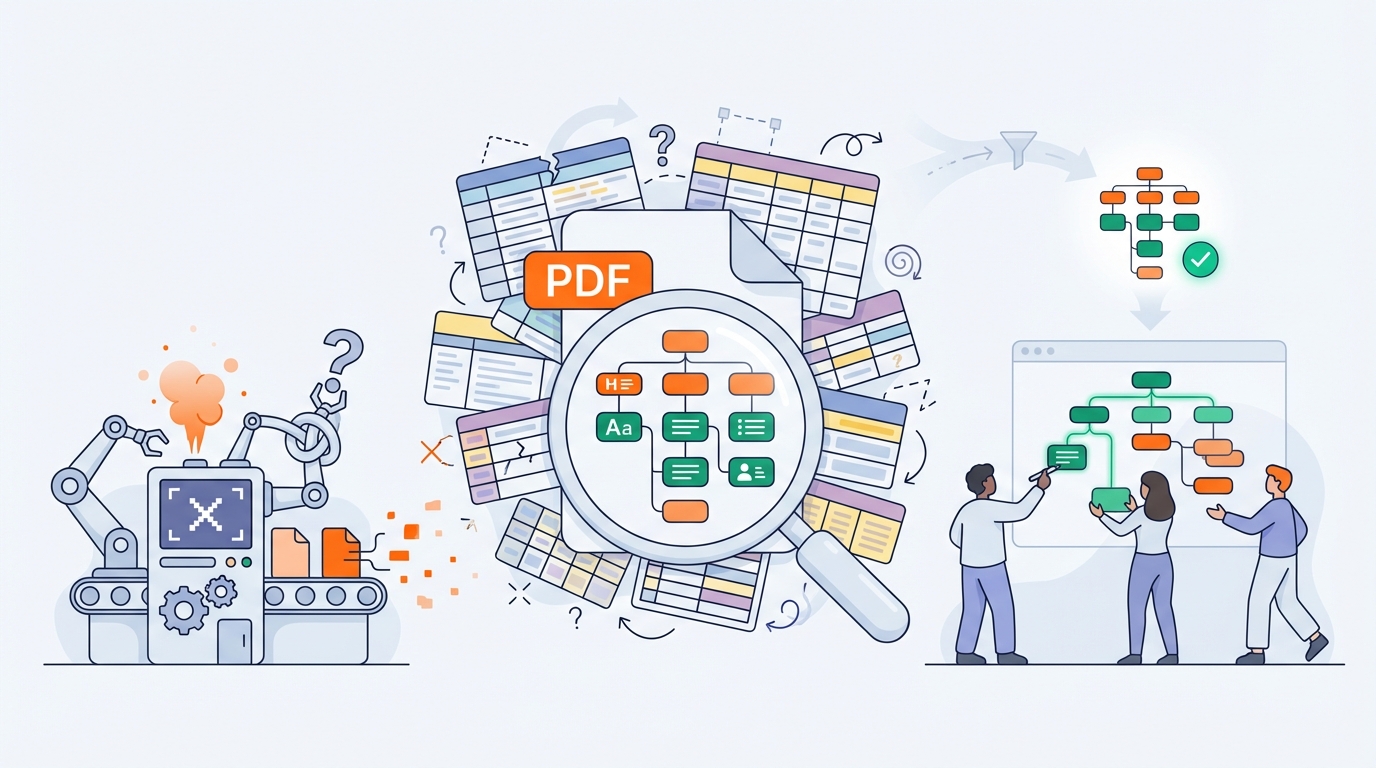
5) De geautomatiseerde oplossing van Elk Solutions
Onze pipeline is ontworpen voor bulk: honderden tot tienduizenden PDF’s, vaak met een beperkt aantal sjablonen (“documenttypes”), maar enorme aantallen bestanden.
Stap 1 — Analyse: wat zit er écht in deze PDF?
We starten met een technische én semantische analyse, zoals:
- bestaat er een tekstlaag (ja/nee),
- tags/structure tree aanwezig (ja/nee en kwaliteit),
- leesvolgorde en artifacts (headers/footers),
- fonts/encodings en Unicode-mapping risico’s,
- tabellen/figuren detectie,
- document properties (titel, taal),
- en een eerste veraPDF-precheck voor PDF/UA (waar faalt hij?).
Output: een diagnoserapport per document + een samenvattend overzicht.

Stap 2 — Groeperen: onderverdeel in documenttypes
Bij grote sites zie je herhaling: hetzelfde sjabloon (besluit, formulier, brochure) komt honderden keren terug.
We clusteren documenten op basis van o.a.:
- paginageometrie en marges,
- typografieprofiel (fontfamilies + groottes),
- header/footer patronen,
- aanwezigheid van tabellen/lijsten,
- herkenbare headings (“Artikel”, “Bijlage”, “Inhoud”),
- en layoutkenmerken (kolommen, sidebars).
Doel: een beperkt aantal documenttypes waarop we gerichte reconstructieregels toepassen.
Stap 3 — Extractie: tekst, fonts en afbeeldingen
Per documenttype extraheren we:
- Tekst: met posities, font-id, stijlkenmerken, en (waar mogelijk) Unicode mapping.
- Fonts: embedding-status en (indien nodig) vervangstrategie.
- Afbeeldingen: raster + vector, resolutie, en context (bijschrift/figuurreferentie).
Belangrijk: we extraheren niet “plat”, maar mét layout- en semantische signalen (kolommen, inspringingen, tabelranden, lijstmarkeringen).
Stap 4 — Herstel van logische structuur (Tagged PDF)
Dit is het hart van toegankelijkheid.
We reconstrueren onder meer:
- Koppenhiërarchie (H1/H2/H3) op basis van typografie + patroonherkenning.
- Paragraafstructuur (alinea’s, witruimte, inspringing).
- Lijsten (bullets/nummering) met correcte nesting.
- Tabellen (rijen/kolommen/headers) inclusief header-assignments en scope.
- Figuur + bijschrift koppelingen, inclusief alt-tekst beleid (automatisch waar mogelijk, anders workflow).
- Leesvolgorde (zeker bij multi-column of complexe layouts).
- Taal en titel (documenttaal en document title als metadata).
Resultaat: een structure tree die inhoudelijk klopt én technisch valideerbaar is.
Stap 5 — Regeneratie: bouw een nieuwe PDF die PDF/UA-proof is
In plaats van “repareren in-place” genereren we de PDF opnieuw, met PDF/UA-eisen als uitgangspunt.
We zorgen daarbij o.a. voor:
- Correcte tagging + marked content mapping.
- Betrouwbare Unicode mapping voor tekst (zoek/kopieer/screenreaders).
- Correcte behandeling van artifacts (headers/footers, paginanummers waar nodig).
- Afbeeldingen met alt-tekst (automatisch of met review-flow).
- Tabellen met correcte headers en relaties.
- Document properties: titel, taal, en consistente metadata.
Optioneel: als je óók archiveringscompliance wilt (bijv. interne archiefregels), kunnen we naast PDF/UA ook een PDF/A-variant genereren die tags ondersteunt (bijv. “-a” conformance in latere PDF/A versies). Maar als jouw primaire doel toegankelijkheid is, is PDF/UA het juiste richtpunt.
Stap 6 — Validatie: controle met veraPDF (PDF/UA)
Na generatie valideren we automatisch met veraPDF.
veraPDF ondersteunt PDF/UA-validatieprofielen en voert machine-verifieerbare checks uit (bij PDF/UA zijn sommige criteria per definitie “human check”, denk aan inhoudelijke kwaliteit van alt-tekst).
We leveren:
- pass/fail per document,
- een machineleesbaar report (JSON/XML),
- en een menselijk leesbaar rapport met concrete foutlocaties.
6) Wat levert het op?
- Aantoonbare document-toegankelijkheid (PDF/UA als concrete norm).
- Veel lagere herstelkosten dan handmatig “retaggen”.
- Schaalbaar: één keer documenttype-rules → duizenden documenten herstellen.
- Audit trail: je kunt aantonen wat er is gecontroleerd en hoe.
7) Praktische implementatie in jouw organisatie
Een typische uitrol:
- Inventarisatie: crawl van je website(s) of ingest via DAM/CMS/DMS.
- Baseline: analyse + clustering + eerste rapportage.
- Pilot: 2–5 documenttypes volledig automatiseren.
- Opschalen: batchverwerking + monitoring op nieuwe uploads.
- Borging: integratie met je publicatieproces (CI/CD, CMS hooks, DMS export).

8) FAQ
“Is PDF/UA genoeg voor WCAG/EN 301 549?”
PDF/UA is de PDF-specifieke invulling van toegankelijkheid. EN 301 549 verwijst voor documenten naar eisen die in lijn liggen met WCAG. In audits zie je daarom vaak: EN 301 549 als juridisch kader + PDF/UA als technische norm voor PDF’s.
“Doen jullie ook OCR voor scans?”
Ja, maar toegankelijkheid vereist dan óók structuurherkenning (koppen, tabellen, leesvolgorde). Dat kan grotendeels automatisch, maar hangt af van scan-kwaliteit en documentcomplexiteit.
“Hoe ga je om met alt-tekst?”
We ondersteunen:
- automatische alt-tekst (waar veilig en voorspelbaar),
- “human-in-the-loop” review voor kritieke figuren,
- en beleid per documenttype (bijv. decoratieve afbeeldingen als artifact).

9) Wil je weten hoe jouw site scoort?
Wij kunnen:
- een snelle scan doen (steekproef of volledige set),
- documenttypes identificeren,
- en een concreet plan geven om naar PDF/UA te migreren, inclusief geautomatiseerde borging.
Stuur ons een set PDF’s of een sitemap, dan laten we je zien wat er mogelijk is.
Bronnen
- Directive (EU) 2016/2102 (Web Accessibility Directive)
https://eur-lex.europa.eu/eli/dir/2016/2102/oj/eng - EN 301 549 v3.2.1 (2021-03)
https://www.etsi.org/deliver/etsi_en/301500_301599/301549/03.02.01_60/en_301549v030201p.pdf - Directive (EU) 2019/882 (European Accessibility Act)
https://eur-lex.europa.eu/eli/dir/2019/882/oj/eng - ISO 14289-1:2014 (PDF/UA-1)
https://www.iso.org/standard/64599.html - PDF Association: ISO 14289 (PDF/UA)
https://pdfa.org/resource/iso-14289-pdfua/ - veraPDF (PDF/A & PDF/UA validator)
https://verapdf.org/
https://docs.verapdf.org/validation/