Video ansehen
Kurzfassung? Sehen Sie das Video. Für den vollen Kontext: Artikel lesen.
PDF ist oft die letzte Meile einer Prozesskette: Was du veröffentlichst, muss archivierbar (Langzeitaufbewahrung) und barrierefrei (für alle nutzbar) sein.
Genau hier wird es knifflig: PDF/A-1a und PDF/UA wirken wie Checkboxen, sind aber in Wirklichkeit ein Bündel konkreter Anforderungen, die eine Pipeline schnell instabil machen können.
In diesem Artikel zeige ich, woran Teams typischerweise scheitern — und wie du das als kontrollierten Prozess statt als „Export am Ende“ aufsetzt.
Warum das so oft schiefgeht
Viele Teams behandeln PDF als Endprodukt: aus Word/HTML exportieren oder per Library generieren. Das klappt… bis die Ausgabe konform sein muss zu:
- PDF/A-1a (Archivqualität, reproduzierbar über Jahre)
- PDF/UA (Barrierefreiheit: Tags, Struktur, Alternativtexte, Lesereihenfolge)
- und manchmal zusätzlichen Anforderungen von Portalen/Branchen/öffentlichen Stellen Dann kommen die Überraschungen:
- „veraPDF schlägt plötzlich fehl nach einer kleinen Änderung.“
- „Die PDF sieht gut aus, aber Screenreader stolpern.“
- „Metadaten passen nicht, Fonts sind nicht eingebettet, Tags sind unvollständig.“

PDF/A-1a vs. PDF/UA in einfachen Worten
PDF/A-1a (Archivierung)
Ziel: Das Dokument soll auch in vielen Jahren zuverlässig gleich dargestellt werden, ohne versteckte Abhängigkeiten.
Typische Stolpersteine:
- Fonts müssen vollständig eingebettet sein
- Farbräume/Profiles müssen stimmen
- Metadaten (XMP) müssen konsistent sein
- keine externen Abhängigkeiten (verlinkte Ressourcen etc.)
PDF/UA (Barrierefreiheit)
Ziel: Eine PDF mit semantischer Struktur, die Hilfstechnologien verstehen.
Typische Anforderungen:
- korrekte Tag-Struktur (Überschriften, Absätze, Listen)
- korrekte Lesereihenfolge
- Alternativtexte für Bilder
- Tabellen müssen echte Tabellen sein (TH/TD, scope/headers)
- Dokumentensprache und Titel korrekt gesetzt
In der Praxis: PDF/A ist „PDF als Archivobjekt“, PDF/UA ist „PDF als strukturiertes Dokument“.
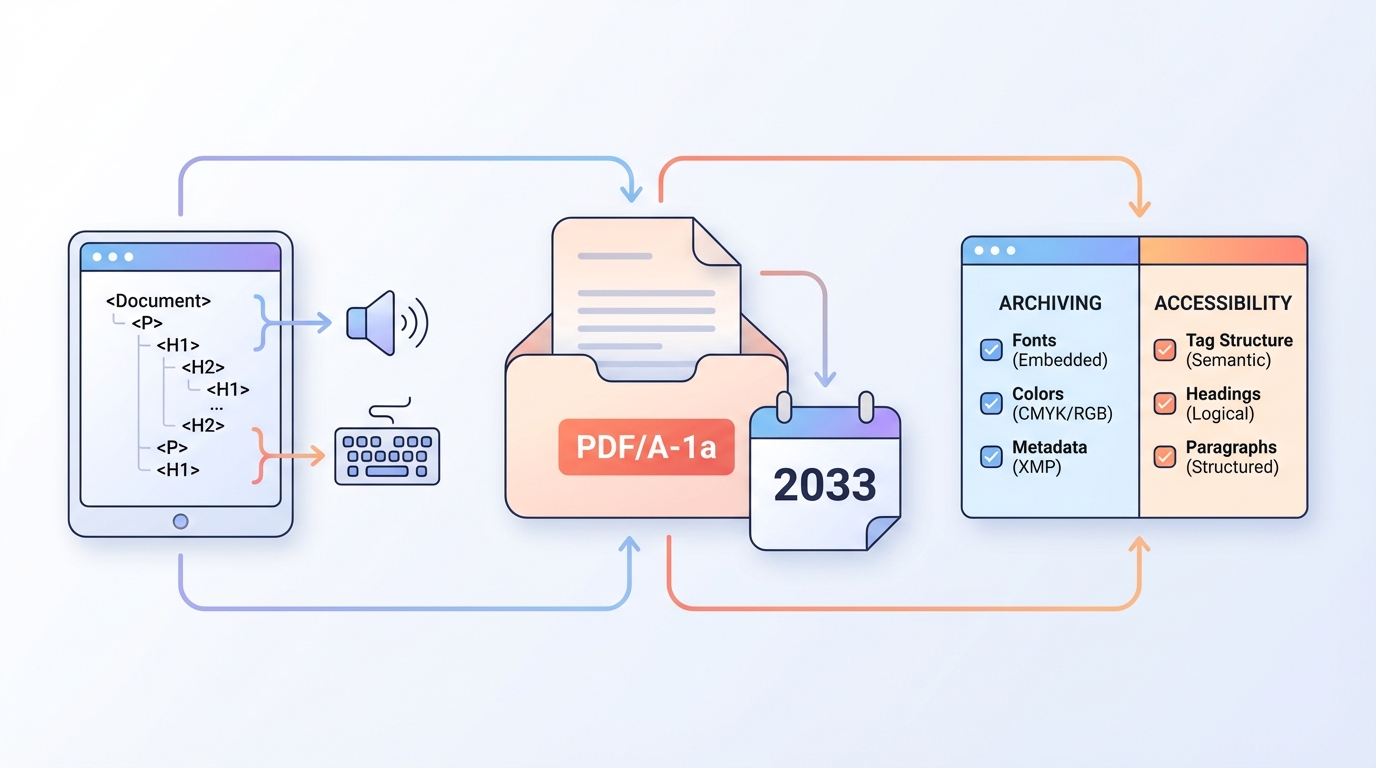
Wo es am häufigsten bricht (Top 10)
- XMP-Metadaten: Titel/Author/Producer fehlen oder sind inkonsistent
- Dokumentensprache fehlt oder ist falsch
- Titel nicht gesetzt (oder nicht als Titel angezeigt)
- Fonts nicht vollständig eingebettet
- Bilder ohne Alt-Text, oder dekorative Bilder nicht als Artefakt markiert
- Überschriftenebenen überspringen Stufen (H1 → H3)
- Lesereihenfolge passt optisch, aber logisch nicht
- Tabellen: fehlende Header / falsches scope
- Links ohne aussagekräftigen Linktext („hier klicken“)
- Generator/Export erzeugt „fast richtige Tags“, aber nicht konforme Tags
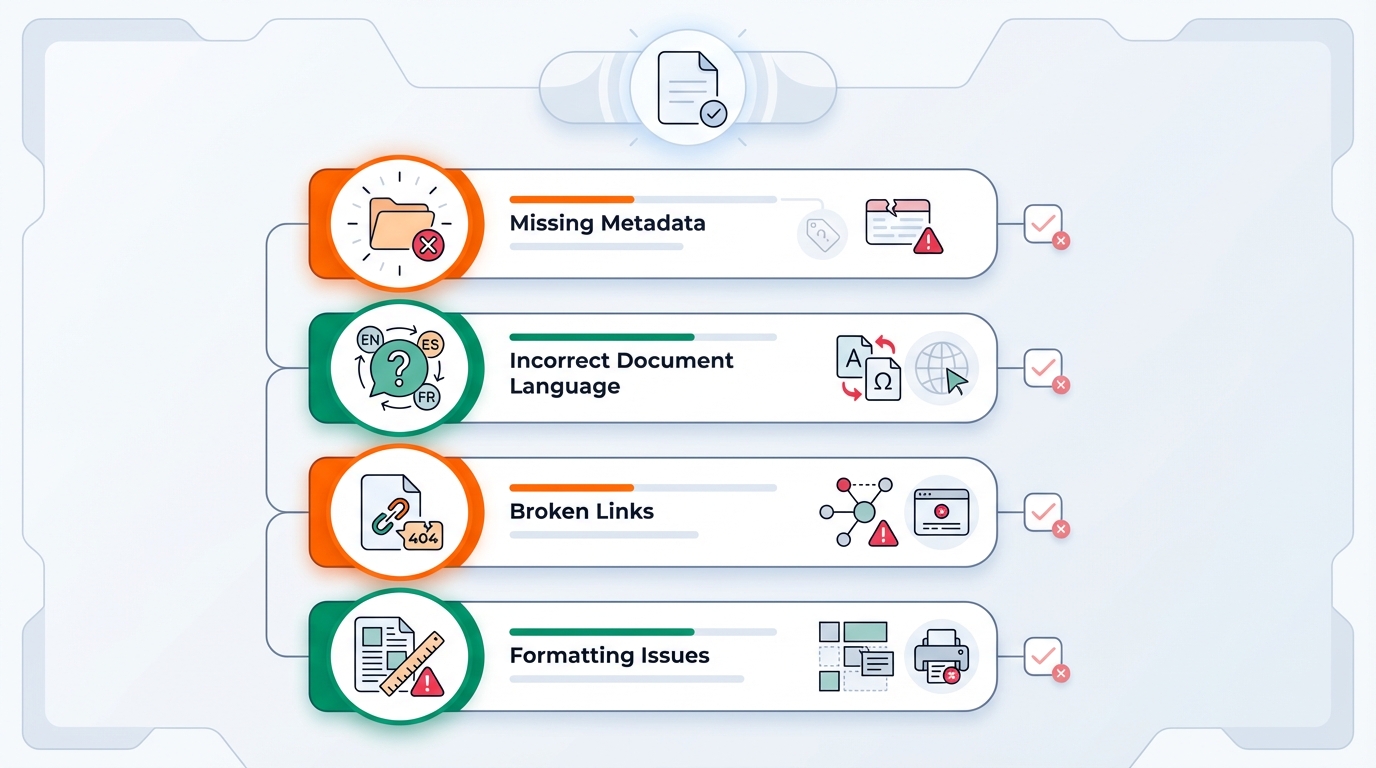
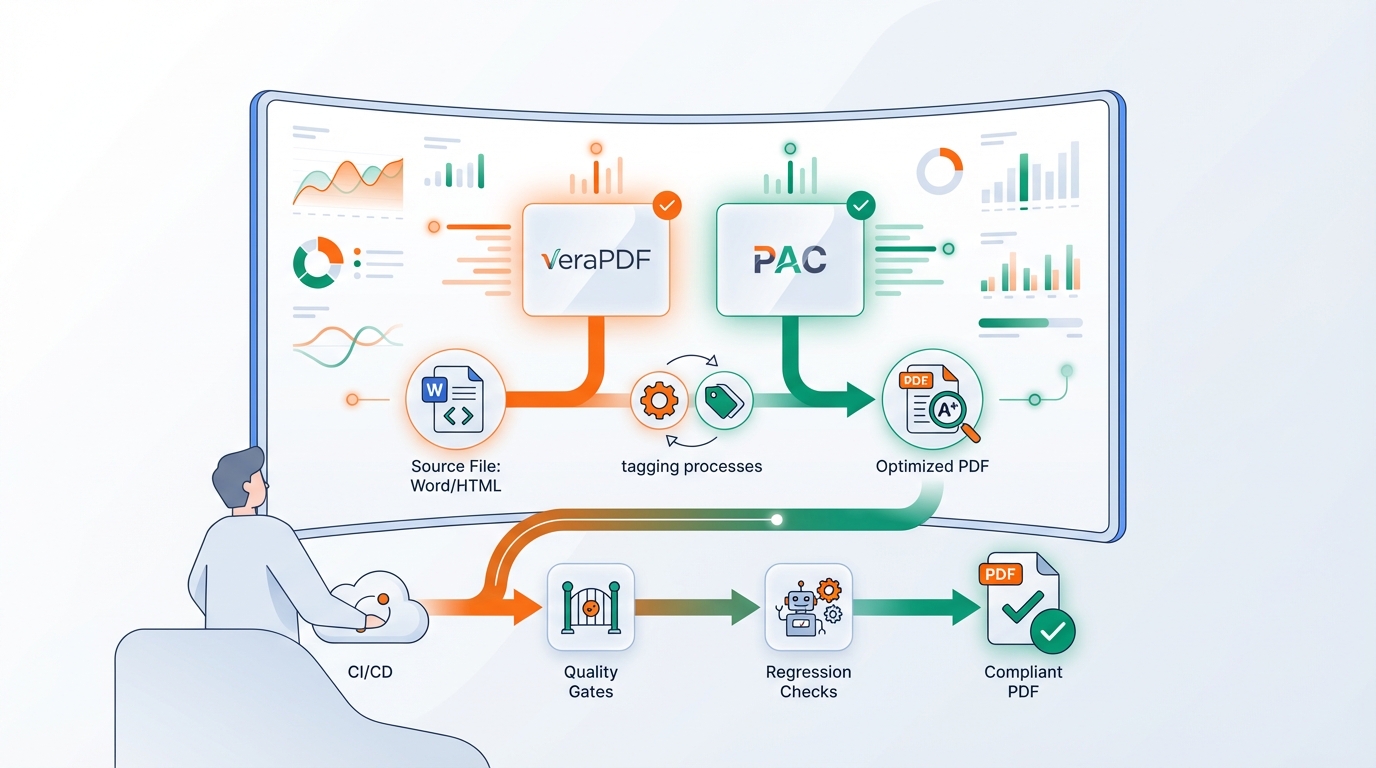
Die Lösung: als kontrollierte Pipeline aufsetzen
Der Schlüssel: PDF/A-1a und PDF/UA nicht als „Export“, sondern als Qualitäts-Gates in deiner Prozesskette behandeln.
1) Eine Quelle der Wahrheit für Metadaten
Lege fest, wo Titel, Autor, Sprache, Datum und Identifikatoren herkommen — und mache das verpflichtend (wie Schema-Validierung bei XML).
2) Tagging ist kein Nebenprodukt
Wenn du aus Word/HTML generierst, definiere klare Mapping-Regeln:
- Überschriften-Styles → H1/H2/H3
- Listen → L/LI
- Tabellen → Table/TR/TH/TD
- Bilder → Figure + Alt-Text oder Artifact
3) Quality Gates vor der Veröffentlichung
Validatoren als Gate nutzen, nicht als „Fehlersuche im Nachhinein“:
- veraPDF für PDF/A (und Teile von PDF/UA)
- ein PDF/UA-Checker (z. B. PAC) für Barrierefreiheit
- eigene Checks ergänzen (fehlende Alt-Texte, Sprache, Titel etc.)
4) Fehler reproduzierbar machen
Wenn eine PDF fehlschlägt, willst du:
- die genaue Validator-Ausgabe speichern
- die Quelleingabe + Version speichern
- sauber sehen, was sich geändert hat (Generator, Stylesheets, Templates)
So vermeidest du „mysteriöse Regressionen“.
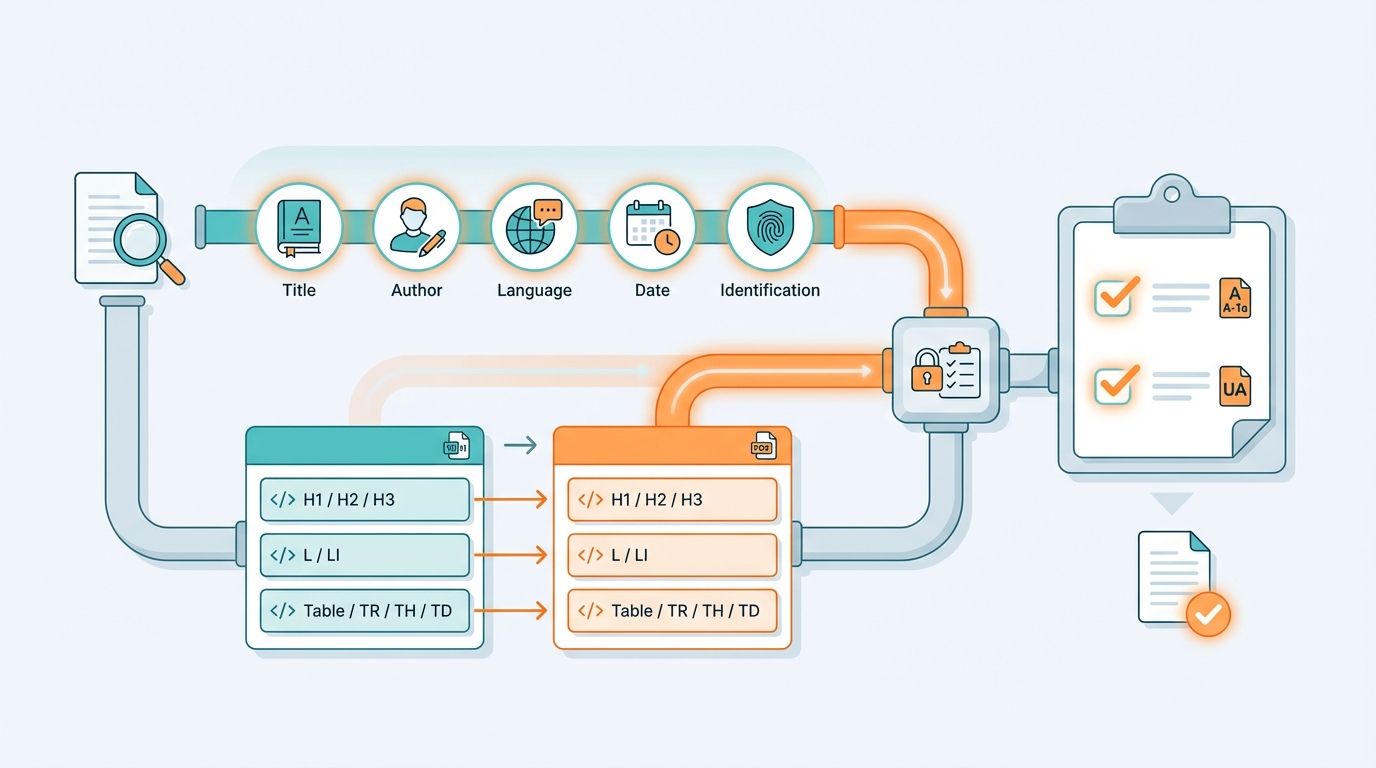
Praktisch starten
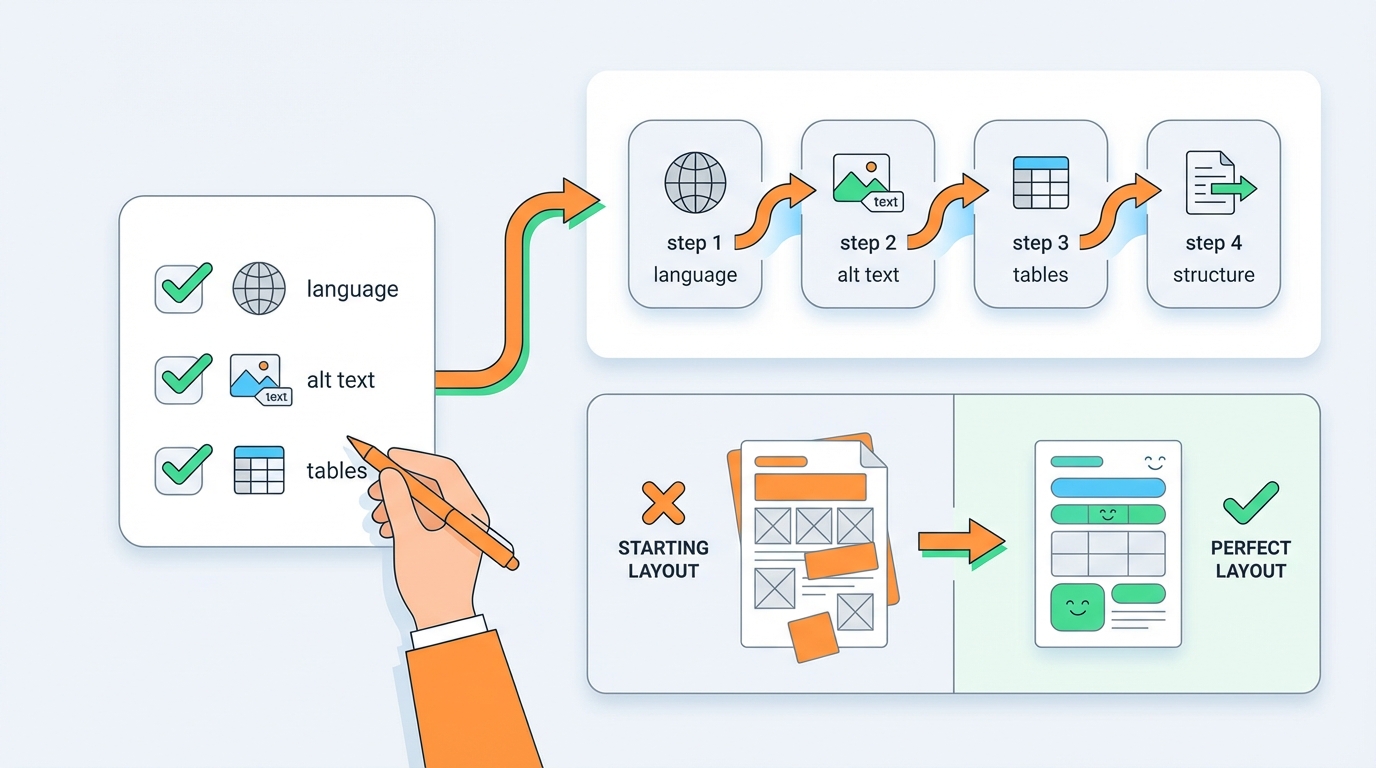
Du musst nicht alles sofort perfekt machen. Starte mit:
- Sprache + Titel immer korrekt
- Alt-Text-Prozess (auch wenn am Anfang manuell)
- Tabellen mindestens als Tabellen erkennbar
- veraPDF als Gate in jedem Build
Danach kannst du die Semantik weiter verbessern (Überschriften, Lesereihenfolge, Artefakte).
Wobei ich helfen kann
Wenn deine PDF/A-1a- oder PDF/UA-Ausgabe „fast konform“ ist (oder nach Änderungen ständig bricht), helfe ich dir, das planbar zu machen:
- Analyse von Failures (veraPDF/PAC) und Root-Cause
- Tagging-Strategie aus deiner Quelle (Word/HTML/XML)
- Quality Gates + Regression Checks in CI/CD
- eine Pipeline, die zuverlässig konforme PDFs erzeugt
Wenn du willst: Schick mir eine Beispiel-PDF plus Validator-Output, dann zeige ich dir die schnellsten Hebel.
Verwendet Ihre Publikationskette noch RenderX XEP?
Lesen Sie, welche XEP-Abhängigkeiten, Regressionen und PDF/UA-Anforderungen vor einer Migration zu Apache FOP messbar sein müssen.