Video ansehen
Kurzfassung? Sehen Sie das Video. Für den vollen Kontext: Artikel lesen.
Viele Organisationen möchten „etwas mit KI“ im Service Desk machen. Verständlich: Ticketvolumen steigt, Wissen ist verteilt, und First-Level-Fragen wiederholen sich ständig. Aber es gibt einen Haken: Ein Chatbot, der gelegentlich falsche Antworten gibt, ist schlimmer als gar keiner. Der entscheidende Punkt ist daher nicht „ein größeres Modell“, sondern: ein System, das du messen, steuern und gezielt verbessern kannst. In diesem Beitrag zeige ich einen praktischen Ansatz aus dem LLM-Ökosystem: DSPy + GEPA.
Warum klassische RAG-Bots oft enttäuschen
Ein typisches Setup ist RAG: Du suchst relevante Passagen aus der Wissensbasis (Confluence, SharePoint, Runbooks) und lässt ein LLM daraus eine Antwort generieren. Das funktioniert… bis es nicht mehr funktioniert. Typische Probleme:
- Der Bot erfindet Details, wenn die Quelle nicht eindeutig ist.
- Antworten klingen überzeugend, passen aber nicht zu euren Prozessen.
- Er eskaliert nicht zuverlässig bei Risiko (Security, Datenschutz, Produktionsvorfälle).
- Antworten werden inkonsistent zwischen Teams und Agents. Was du wirklich willst, ist KI, die sich wie ein guter Service-Desk-Kollege verhält: quellenbasiert, kurz, fragt nach fehlenden Infos und weiß, wann sie übergeben muss.

Kernidee: KI als Programm statt als einzelner Prompt
Hier kommt DSPy ins Spiel. Statt eines riesigen Prompts baust du deinen Service-Desk-Assistenten als Pipeline:
-
Klassifikation
Ist das ein Incident, eine How-to-Frage, ein Account-Thema, ein Change Request? -
Retrieval (Wissenssuche)
Ziehe die passenden Quellen: KB-Artikel, Runbooks, Policies, Known Issues. -
Antwortgenerierung
Erzeuge eine Antwort mit:- klaren Schritten
- passendem Ton (freundlich, direkt)
- Quellenverweisen (Zitate oder Links)
-
Validierung / „Confidence Gate“
Prüfe, ob genügend Evidenz in den Quellen vorhanden ist.
Wenn nicht: gezielt nachfragen oder eskalieren.
Das klingt einfach, ist aber ein großer Unterschied: Jede Stufe kann separat getestet, gemessen und optimiert werden.
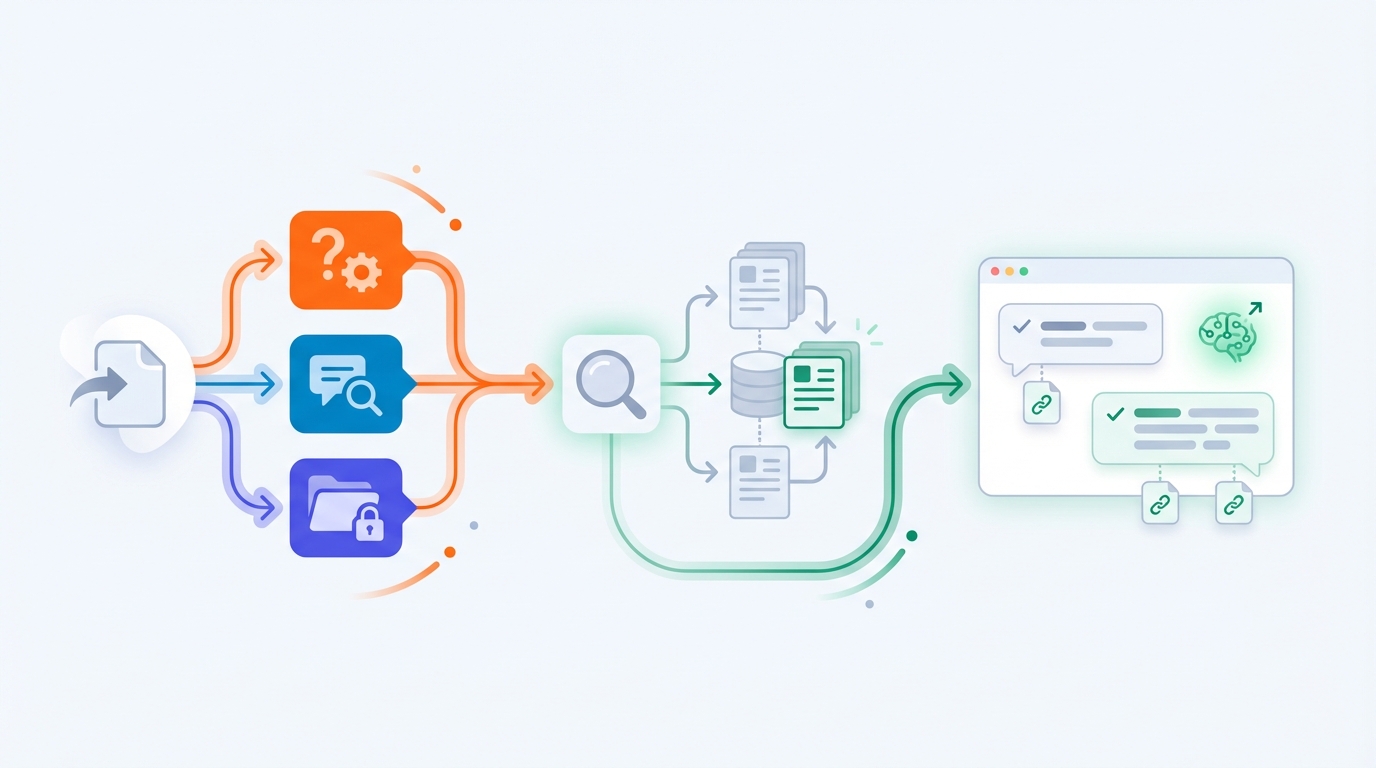
GEPA: Prompts automatisch verbessern – mit echten Tickets
Wie wird diese Pipeline nun wirklich gut?
Dafür nutzt du GEPA (einen Optimizer in Kombination mit DSPy). Anstatt manuell Prompts zu feilen:
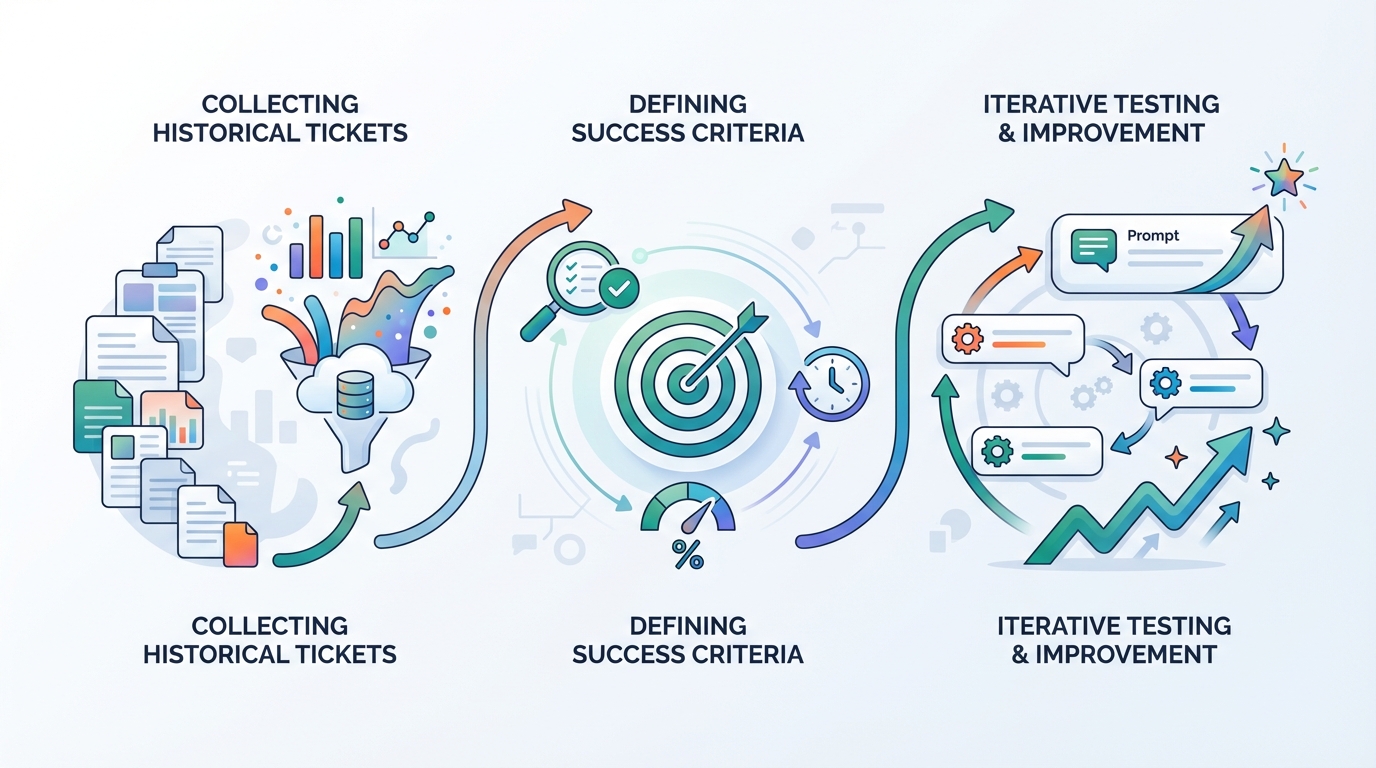
- Nimm historische Tickets (z. B. 500–2000).
- Definiere, was „gut“ heißt: korrekt, richtige Schritte, richtige Eskalation, quellenbasiert, passender Ton.
- Lass GEPA Varianten der Prompts/Instruktionen entlang der Pipeline testen.
- Behalte, was besser funktioniert, und entwickle darauf weiter.
Das ist im Prinzip „Unit Tests“ für KI-Verhalten – nicht für Code.
Wie sieht eine gute Bewertungsmetrik aus?
Das ist der wichtigste Teil. Wenn du nur „klingt gut“ misst, bekommst du eine KI, die überzeugend formuliert. Wenn du misst, was du wirklich brauchst, bekommst du Zuverlässigkeit.
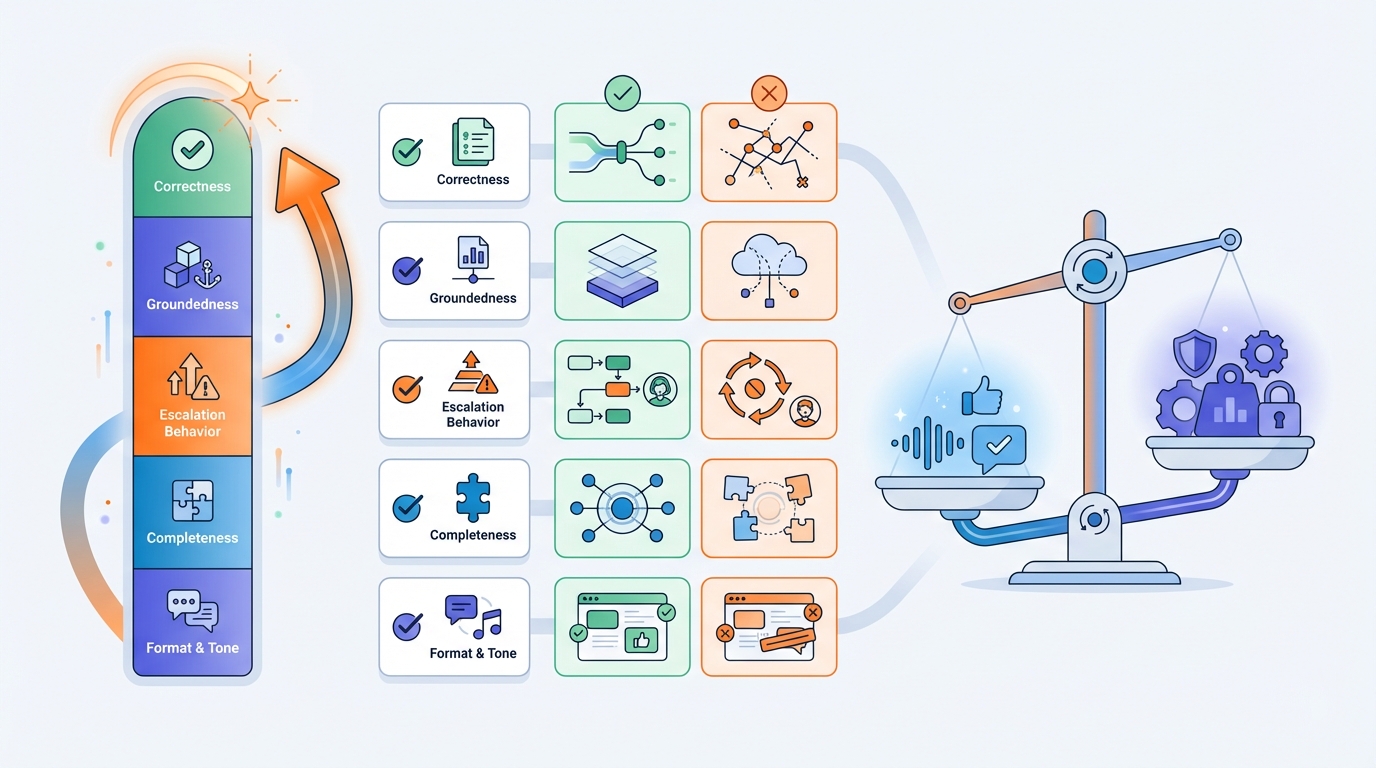
Für Service-Desk-Antworten kannst du z. B. bewerten:
- Korrektheit (stimmt es fachlich?)
- Groundedness (ist es durch Quellen belegt oder geraten?)
- Eskalationsverhalten (bei Unsicherheit oder Risiko: an Menschen übergeben)
- Vollständigkeit (keine kritischen Schritte fehlen)
- Format & Ton (kurz, umsetzbar, klare Next Steps)
Die Metrik kann teils automatisiert sein (Regeln/Checks/Tests) und teils über „Judge“-Bewertungen laufen (LLM-as-judge), idealerweise mit regelmäßigen menschlichen Stichproben.
Sicherer Rollout: erst „Draft Mode“, dann Autonomie
Ein kluger Einstieg ist ein Assistent, der:
- Antwortentwürfe für Agents erstellt,
- die relevanten Quellen mitliefert,
- und das „Warum“ sichtbar macht (Zitate + Confidence).
Das bringt schnell messbaren Nutzen: schnellere Antworten, weniger Suchaufwand, mehr Konsistenz – ohne sofort volle Autonomie.
Wenn die Evaluations stabil sind, kannst du schrittweise zu teilweiser oder voller Autonomie übergehen.
Was du dafür brauchst
In der Praxis sind das die Bausteine:
-
Wissensbasis als „Single Source of Truth“
Confluence/SharePoint/Markdown/PDF/Runbooks (am besten gepflegt und gut auffindbar). -
Historische Tickets
Für Training/Evaluation. (Oft ist Anonymisierung/Redaktion nötig – Datenschutz.) -
Klare Policies & Guardrails
Was darf der Bot? Wann muss er immer eskalieren? -
Ein Evaluation-Loop
Regelmäßig denselben Test-Satz ausführen, um Regressionen zu erkennen (CI/CD für KI-Verhalten).
Wann sich das besonders lohnt
DSPy + GEPA ist besonders spannend, wenn:
- viele Tickets wiederkehrend sind,
- Wissen fragmentiert ist,
- Fehler teuer sind (Security, Datenschutz, Produktion),
- und du messbare Verbesserung willst – nicht nur „fühlt sich besser an“.
Willst du das auf deinen Service Desk anwenden?
Wenn du mir sagst:
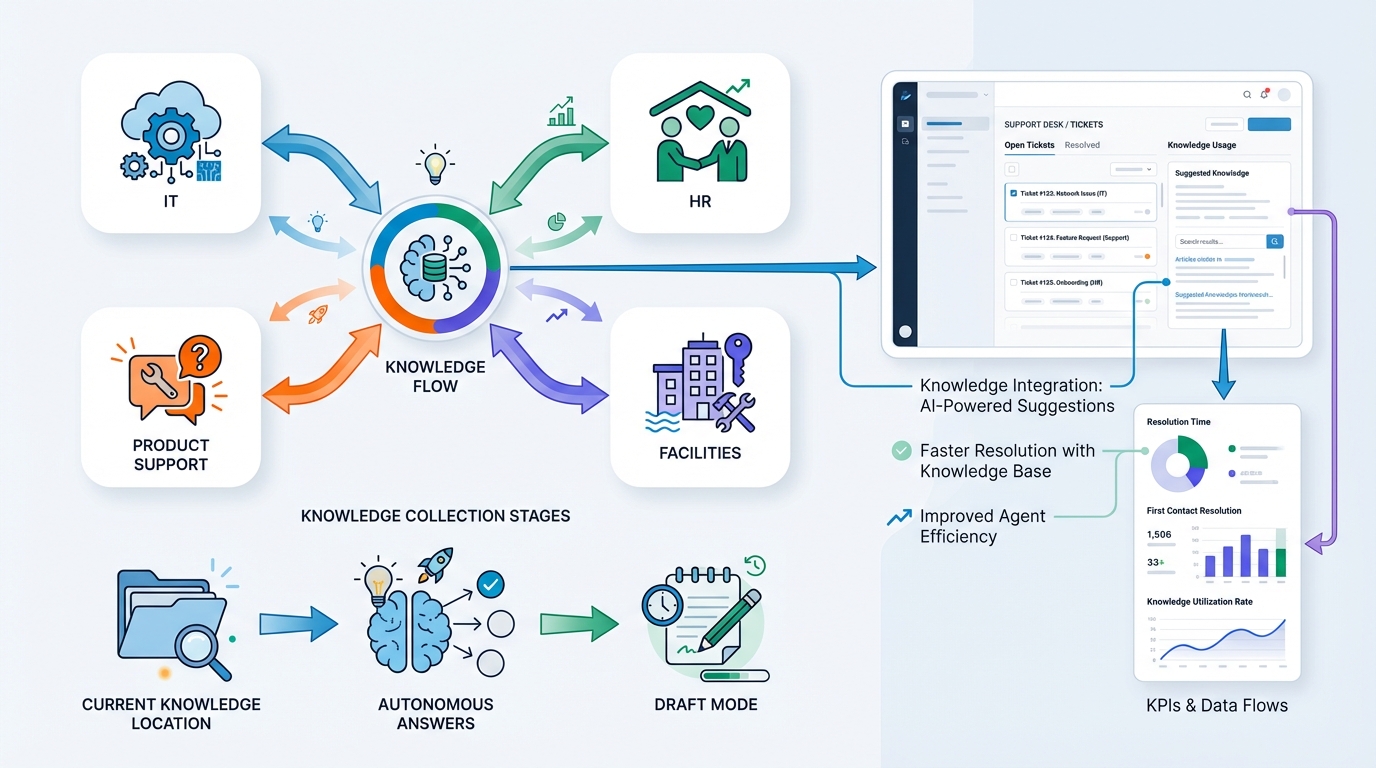
- das Fachgebiet (IT, Produkt-Support, HR, Facilities),
- wo euer Wissen liegt,
- und ob du autonom antworten willst oder zuerst „Draft Mode“,
kann ich einen konkreten Plan skizzieren: Pipeline-Design, Dataset-Aufbau, Metriken und Integration in euer Ticket-System (Zendesk/Jira/ServiceNow/Teams).