Video ansehen
Kurzfassung? Sehen Sie das Video. Für den vollen Kontext: Artikel lesen.
Viele Organisationen haben Hunderte (oder Tausende) PDFs auf ihrer Website, die nicht den Anforderungen von PDF/UA (ISO 14289) entsprechen. Das klingt nach einem technischen Detail, betrifft in der Praxis aber unmittelbar gesetzliche Anforderungen an Barrierefreiheit – und die Nutzbarkeit Ihrer Informationen für alle (Screenreader, Tastaturnavigation, Wiederverwendung von Text). In diesem Beitrag erfahren Sie:
- was PDF/UA genau ist und warum bestehende PDFs häufig scheitern,
- wie europäische Vorgaben zur digitalen Barrierefreiheit auf PDFs wirken,
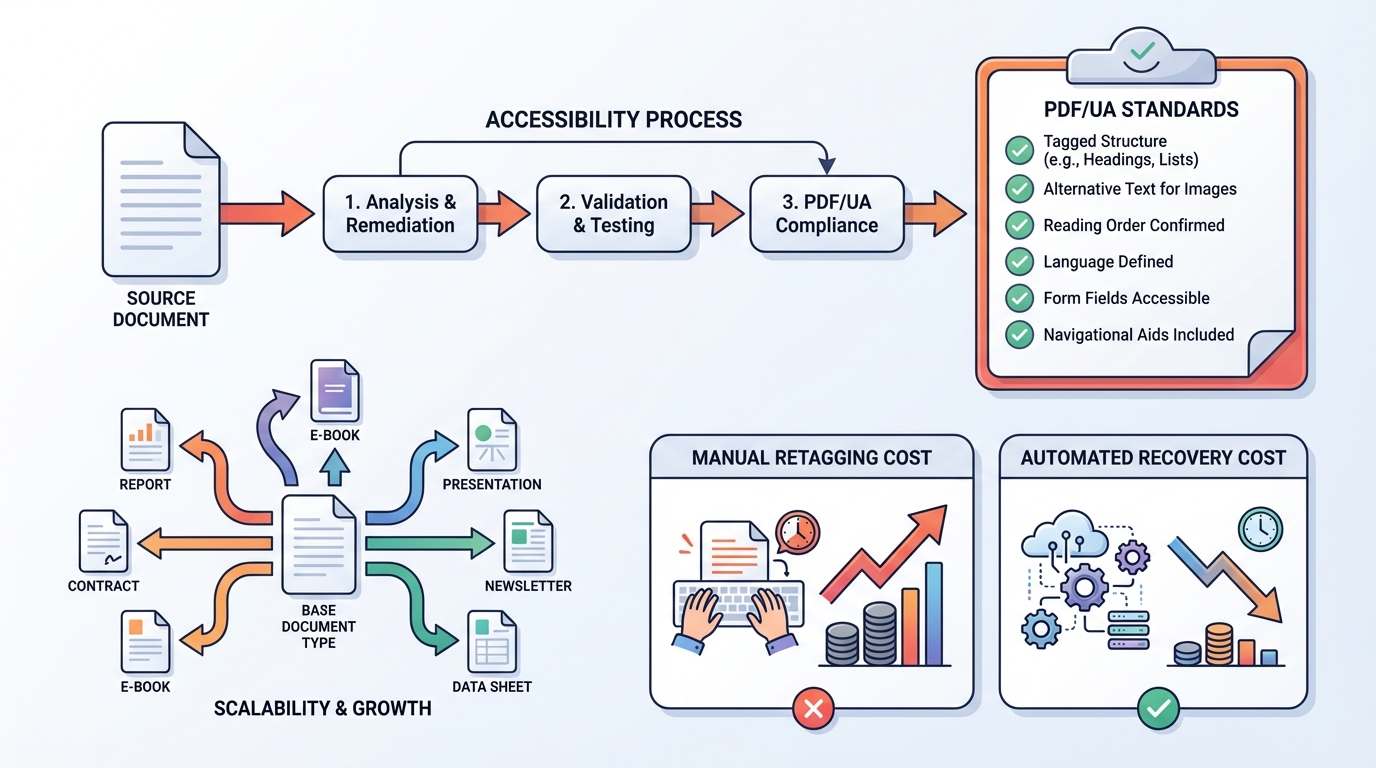
- und wie Elk Solutions das automatisiert löst: analysieren → klassifizieren → rekonstruieren → regenerieren → mit veraPDF validieren.
1) Warum Ihre aktuellen PDFs oft „nicht barrierefrei“ sind
Ein PDF kann visuell perfekt aussehen und dennoch nicht barrierefrei sein. Typische Ursachen:
- Keine Tags (Tagged PDF) → Screenreader erkennen nicht, was Überschriften, Absätze, Listen und Tabellen sind.
- Falsche Lesereihenfolge → mehrspaltige Layouts, Textboxen, Fußnoten, Kopf-/Fußzeilen geraten durcheinander.
- Bilder ohne Alternativtext → wichtige Informationen fehlen für assistive Technologien.
- Tabellen ohne Header/Scope → Beziehungen zwischen Zeilen-/Spaltenüberschriften und Zellen sind unklar.
- Unzuverlässige Textextraktion → Fonts/Encodings haben kein korrektes Unicode-Mapping.
- Dokumentsprache fehlt → Screenreader können nicht korrekt zwischen Sprachen wechseln.

2) Ist das in Europa eine gesetzliche Pflicht?
Europa schreibt in der Regel nicht „PDF/UA“ als verpflichtendes Dateiformat vor, wohl aber die Barrierefreiheit digitaler Informationen.
Öffentlicher Sektor: Web Accessibility Directive (EU 2016/2102)
Für Websites und Apps von öffentlichen Stellen gilt eine Barrierefreiheitspflicht (einschließlich der veröffentlichten Dokumente). Die Richtlinie verweist für die technische Umsetzung auf einen europäischen Standard: EN 301 549.
Quellen: Richtlinie (EU) 2016/2102 und EN 301 549.
- https://eur-lex.europa.eu/eli/dir/2016/2102/oj/eng
- https://www.etsi.org/deliver/etsi_en/301500_301599/301549/03.02.01_60/en_301549v030201p.pdf
Breiter (abhängig vom Anwendungsbereich): European Accessibility Act (EU 2019/882)
Der European Accessibility Act erweitert Barrierefreiheitsanforderungen auf eine Reihe von Produkten und Dienstleistungen (mit nationaler Umsetzung) und gilt ab 28. Juni 2025.
Praktische Konsequenz: Wenn Sie PDFs als Teil Ihrer digitalen Dienstleistungen oder Ihrer öffentlichen Informationsbereitstellung veröffentlichen, sollten Sie davon ausgehen, dass sie barrierefrei sein müssen. PDF/UA ist die am häufigsten genutzte Norm, um „barrierefreies PDF“ konkret zu machen, weil sie exakt definiert, was ein PDF für assistive Technologien benötigt.
3) Was ist PDF/UA genau?
PDF/UA (Universal Accessibility) ist die ISO-Norm ISO 14289-1 für barrierefreie PDFs.
Ziel ist, dass ein PDF:
- semantisch ist (Überschriften, Absätze, Listen, Tabellen, Abbildungen),
- Navigation unterstützt (Lesereihenfolge, ggf. Lesezeichen),
- Text zuverlässig extrahierbar ist (Unicode-Mapping),
- und die richtigen „Accessibility Hooks“ enthält (z. B. Alternativtexte, Dokumentsprache, Tabellenüberschriften).
Nützliche Einstiegsquellen:
- ISO 14289-1:2014: https://www.iso.org/standard/64599.html
- PDF Association Überblick: https://pdfa.org/resource/iso-14289-pdfua/
4) Warum eine schnelle „Konvertierung“ oft nicht funktioniert
Viele Tools versprechen „Make accessible“ oder „Auto-tag“. In der Praxis scheitert das häufig, weil:
- das Quell-PDF keine Semantik enthält (das Tool muss raten),
- Tabellen/Spalten/Fußzeilen falsch interpretiert werden,
- und „Tags, die technisch existieren“ noch nicht bedeuten, dass der Inhalt logisch korrekt ist.
Darum ist unser Ansatz anders: Wir rekonstruieren das Dokument explizit auf Basis eines Inhaltsmodells pro Dokumenttyp.
5) Die automatisierte Lösung von Elk Solutions
Unsere Pipeline ist für Skalierung gebaut: Hunderte bis Zehntausende PDFs – meist mit einer begrenzten Anzahl an Vorlagen („Dokumenttypen“), aber sehr hohen Stückzahlen.
Schritt 1 — Analyse: Was steckt wirklich in diesem PDF?
Wir starten mit einer technischen und semantischen Analyse, z. B.:
- gibt es eine Textebene (ja/nein),
- sind Tags/Strukturbaum vorhanden (ja/nein und Qualität),
- Lesereihenfolge und Artifacts (Kopf-/Fußzeilen),
- Fonts/Encodings und Risiken beim Unicode-Mapping,
- Erkennung von Tabellen/Abbildungen,
- Dokumenteigenschaften (Titel, Sprache),
- und ein erster veraPDF-Precheck für PDF/UA (wo scheitert es?).
Output: ein Diagnosebericht pro Dokument + eine konsolidierte Übersicht.

Schritt 2 — Klassifizierung: Aufteilen in Dokumenttypen
Auf großen Websites wiederholt sich vieles: dieselbe Vorlage (Beschluss, Formular, Broschüre) erscheint hunderte Male.
Wir clustern Dokumente u. a. nach:
- Seitengeometrie und Rändern,
- typografischem Profil (Schriftfamilien + Größen),
- Kopf-/Fußzeilenmustern,
- Vorhandensein von Tabellen/Listen,
- erkennbaren Überschriften („Artikel“, „Anlage“, „Inhalt“),
- Layoutmerkmalen (Spalten, Sidebars).
Ziel: eine kleine Anzahl Dokumenttypen, auf die wir gezielte Rekonstruktionsregeln anwenden.
Schritt 3 — Extraktion: Text, Fonts und Bilder
Pro Dokumenttyp extrahieren wir:
- Text: mit Positionen, Font-IDs, Stilsignalen und (wo möglich) Unicode-Mapping.
- Fonts: Einbettungsstatus und (falls nötig) Ersatzstrategie.
- Bilder: Raster + Vektor, Auflösung und Kontext (Bildunterschrift/Abbildungsreferenz).
Wichtig: Wir extrahieren nicht „flach“, sondern erhalten Layout- und Semantiksignale (Spalten, Einzüge, Tabellenlinien, Listenmarker).
Schritt 4 — Logische Struktur wiederherstellen (Tagged PDF)
Das ist der Kern der Barrierefreiheit.
Wir rekonstruieren u. a.:
- Überschriftenhierarchie (H1/H2/H3) anhand Typografie + Mustererkennung.
- Absatzstruktur (Blöcke, Weißraum, Einzüge).
- Listen (Aufzählungen/Nummerierung) mit korrekter Verschachtelung.
- Tabellen (Zeilen/Spalten/Header) inkl. Header-Zuordnung und Scope.
- Abbildung + Bildunterschrift-Beziehungen inkl. Alt-Text-Policy (automatisch wo möglich, sonst Workflow).
- Lesereihenfolge (besonders bei mehrspaltigen/komplexen Layouts).
- Sprache und Titel (Dokumentsprache und Dokumenttitel in Metadaten).
Ergebnis: ein Strukturbaum, der inhaltlich stimmt und technisch validierbar ist.
Schritt 5 — Regenerierung: Ein neues PDF erzeugen, das PDF/UA-proof ist
Statt „in-place zu patchen“ generieren wir das PDF neu – mit PDF/UA-Anforderungen als Ausgangspunkt.
Wir stellen u. a. sicher:
- Korrektes Tagging + Marked-Content-Mapping.
- Zuverlässiges Unicode-Mapping für Text (Suchen/Kopieren/Screenreader).
- Korrekte Behandlung von Artifacts (Kopf-/Fußzeilen, Seitenzahlen wo sinnvoll).
- Bilder mit Alternativtext (automatisch oder via Review-Flow).
- Tabellen mit korrekten Headers und Beziehungen.
- Dokumenteigenschaften: Titel, Sprache und konsistente Metadaten.
Optional: Wenn Sie zusätzlich Archivierungs-Compliance benötigen (z. B. interne Akten-/Aufbewahrungsregeln), können wir auch eine PDF/A-Variante erzeugen, die Tagging unterstützt (z. B. „-a“-Konformität in späteren PDF/A-Versionen). Wenn Ihr Hauptziel jedoch Barrierefreiheit ist, ist PDF/UA das richtige Ziel.
Schritt 6 — Validierung: Prüfung mit veraPDF (PDF/UA)
Nach der Regenerierung validieren wir automatisch mit veraPDF.
veraPDF unterstützt PDF/UA-Validierungsprofile und führt maschinenprüfbare Checks aus (bei PDF/UA sind manche Anforderungen naturgemäß „Human Check“, z. B. die Qualität von Alternativtexten).
Wir liefern:
- Pass/Fail pro Dokument,
- einen maschinenlesbaren Report (JSON/XML),
- und einen lesbaren Bericht mit konkreten Fehlerstellen.
6) Was bringt das?
- Nachweisbare Dokument-Barrierefreiheit (PDF/UA als konkrete Norm).
- Deutlich geringere Sanierungskosten als manuelles Retagging.
- Skalierbar: Dokumenttyp-Regeln einmal definieren → tausende Dokumente beheben.
- Audit-Trail: Sie können belegen, was geprüft wurde und wie.
7) Praktische Einführung in Ihrer Organisation
Typischer Ablauf:
- Inventarisierung: Crawl Ihrer Website(s) oder Ingest via DAM/CMS/DMS.
- Baseline: Analyse + Clustering + erste Reports.
- Pilot: 2–5 Dokumenttypen Ende-zu-Ende automatisieren.
- Skalierung: Batch-Verarbeitung + Monitoring neuer Uploads.
- Governance: Integration in Ihren Publishing-Workflow (CI/CD, CMS-Hooks, DMS-Export).

8) FAQ
„Reicht PDF/UA für WCAG/EN 301 549?“
PDF/UA ist die PDF-spezifische Umsetzung von Barrierefreiheit. EN 301 549 referenziert Anforderungen für Dokumente, die mit WCAG in Einklang stehen. In Audits sieht man deshalb oft: EN 301 549 als Rahmen + PDF/UA als technische Norm für PDFs.
„Unterstützen Sie auch OCR für Scans?“
Ja – aber Barrierefreiheit erfordert zusätzlich Strukturerkennung (Überschriften, Tabellen, Lesereihenfolge). Das lässt sich weitgehend automatisieren, hängt aber von Scanqualität und Dokumentkomplexität ab.
„Wie gehen Sie mit Alternativtext um?“
Wir unterstützen:
- automatische Alternativtexte (wo sicher und zuverlässig),
- Human-in-the-loop Review für kritische Abbildungen,
- und Policies pro Dokumenttyp (z. B. dekorative Bilder als Artifacts).

9) Möchten Sie wissen, wie Ihre Website abschneidet?
Wir können:
- einen schnellen Scan durchführen (Stichprobe oder kompletter Bestand),
- Dokumenttypen identifizieren,
- und einen konkreten Plan für die Migration zu PDF/UA liefern – inklusive automatisierter Absicherung im Prozess.
Senden Sie uns eine PDF-Sammlung oder eine Sitemap, dann zeigen wir Ihnen, was möglich ist.
Quellen
- Directive (EU) 2016/2102 (Web Accessibility Directive)
https://eur-lex.europa.eu/eli/dir/2016/2102/oj/eng - EN 301 549 v3.2.1 (2021-03)
https://www.etsi.org/deliver/etsi_en/301500_301599/301549/03.02.01_60/en_301549v030201p.pdf - Directive (EU) 2019/882 (European Accessibility Act)
https://eur-lex.europa.eu/eli/dir/2019/882/oj/eng - ISO 14289-1:2014 (PDF/UA-1)
https://www.iso.org/standard/64599.html - PDF Association: ISO 14289 (PDF/UA)
https://pdfa.org/resource/iso-14289-pdfua/ - veraPDF (PDF/A & PDF/UA validator)
https://verapdf.org/
https://docs.verapdf.org/validation/